Rechtsfragen und rechtliche Handlungsbedarfe bei KI-basierten Text- und Bildgeneratoren
Anwendungen Künstlicher Intelligenz (KI) wie der auf dem Sprachmodell ChatGPT basierende Chatbot und der Bildgenerator DALL·E des US-Anbieters OpenAI sind binnen kürzester Zeit weit über die Ausprobierphase hinaus im Alltag der Hochschulen angekommen. Ähnliches gilt für Dienste wie Luminous, Neuroflash, Stable Diffusion oder Midjourney. Lehrende und Hochschulleitungen diskutieren parallel die Potenziale und Herausforderungen einer strategischen Implementierung maschinengenerierter Systeme* in die Hochschullehre. Diese wirft eine Vielzahl didaktischer und prüfungsorganisatorischer Fragen auf – und ist auch in rechtlicher Hinsicht komplex.
Nachfolgend werden ausgewählte Rechtsfragen und Handlungsbedarfe, die mit dem Einsatz generativer KI-Modelle in der Hochschullehre einhergehen, erörtert. Der Fokus liegt auf dem Urheberrecht und Datenschutz – nicht Gegenstand des Beitrags sind die (nicht minder relevanten) prüfungsrechtlichen Faktoren. Die Darstellung orientiert sich an Diensten wie ChatGPT und DALL·E, ist aber in vielen Punkten auf andere generative KI-Modelle übertragbar. Der Großteil der Einordnungen, hier fokussiert auf Hochschulen, gilt für den Schulbereich und andere Bildungseinrichtungen entsprechend.
Zu berücksichtigen ist, dass sich die KI-Dienste in rasantem Tempo weiterentwickeln und es zu den aufgeworfenen Fragen noch so gut wie keine Rechtsprechung und auch keine gefestigte Rechtsliteratur gibt. Insoweit handelt es sich um eine erste Orientierung und eine Momentaufnahme. Ausgangspunkt der Bewertungen ist die Rechtslage in Deutschland.
*Generative KI-Modelle basieren grundlegend auf Machine Learning Techniken wie Unsupervised und Semi-Supervised Learning, um große Mengen an Daten zu verarbeiten und daraus Neues zu generieren.
Übersicht über die zehn im Beitrag behandelten Fragen:
- Entsteht ein Urheberrecht an KI-generierten Ergebnissen?
- Wie wirkt es sich aus, dass ein Großteil des KI-Trainingskorpus sich aus urheberrechtlich geschützten Werken und Materialien zusammensetzt?
- Darf KI-generierter Output in Lehrmaterialien oder Hausarbeiten genutzt werden?
- Ist es urheberrechtlich zulässig, ein Werk „im Stil von (Künstler:in/Fotograf:in XY)“ zu generieren und weiter zu verwenden, z. B. in einem Skript oder in einer Hausarbeit?
- Wie kennzeichne ich als Lehrende:r oder Studierende:r eigene KI-generierte Erzeugnisse in meinen Materialien/Arbeiten, wie zitiere ich fremde KI-generierte Erzeugnisse, und wie gehe ich hinsichtlich der Hilfsmittelangabe vor?
- Ist KI-Output OER-fähig, d. h. kann er als Open Educational Resource frei zur Nachnutzung lizenziert werden?
- Worauf muss ich achten, wenn ich Texte, Fotos, Bilder etc. im Zuge einer Eingabe in die KI-Dienste einspeise?
- Stichwort Datenschutz: Welche Daten von Nutzenden werden bei Nutzung der Text-/Bildgeneratoren verarbeitet?
- Auf welche Rechtsgrundlage lässt sich der Einsatz von KI-Diensten wie ChatGPT in der Hochschullehre stützen?
- Welche datenschutzrechtlichen Verpflichtungen kommen auf Hochschulen bei Nutzung generativer KI-Modelle zu?
1. Entsteht ein Urheberrecht an KI-generierten Ergebnissen?
Die Beantwortung dieser Frage hängt davon ab, was die Nutzer:innen im Zuge einer Anfrage eingeben oder hochladen, wie sie die KI nutzen und ob der Output der KI von ihnen weiterbearbeitet wird.
Sind die Ergebnisse, die bewertet werden sollen, rein KI-erzeugt, kommt ein Urheberrechtsschutz nach derzeitiger Rechtslage nicht in Frage.
Handelt es sich hingegen um Arbeitsergebnisse mit einem nicht unerheblichen schöpferischen, d. h. gestalterischen, Anteil von Menschen, die unter KI-Mitwirkung entstanden sind, ist ein Urheberrechtsschutz zumindest denkbar. Dies kann etwa der Fall sein, wenn Lehrende den Dienst anweisen, einen selbst verfassten Text (oder Programmiercode etc.) nach bestimmten Vorgaben nicht unerheblich umzuschreiben – oder diese umgekehrt einen KI-generierten Text nach der Ausgabe umfänglich bearbeiten, also nach ihren Vorstellungen stark verändern bzw. Inhalte ergänzen und die Ausdrucksweise in ihrem Sinne anpassen.
Zum rechtlichen Hintergrund: Urheberrechtlich geschützte Werke sind nur persönliche geistige Schöpfungen, also vom Menschen geschaffene Ergebnisse. Da KI-generierte Erzeugnisse in Gestalt von Texten, Bildern, Musik, Code etc. das Ergebnis sog. neuronaler Netze sind, scheidet bei ihnen mangels Erstellung durch einen Menschen ein Urheberrechtsschutz grundsätzlich aus.
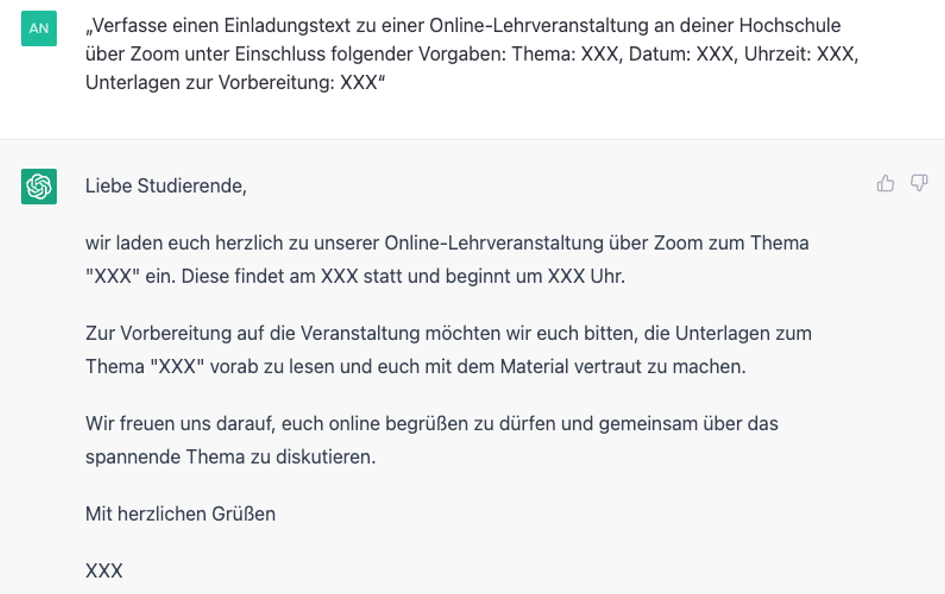
Dies ist etwa der Fall bei Übersetzungsdiensten wie Google Translate oder DeepL, nach Einfügen einer zu übersetzenden Textpassage in die Eingabemaske. Hier wird maximal die Eingabe bzw. ein Tastenbefehl benötigt, um die Übersetzung in eine bestimmte Sprache zu generieren. Das Ergebnis ist hier rein KI-erzeugt. Auch entsteht bei Diensten wie ChatGPT-3, wenn die einfache Eingabe (der sog. „Prompt“) lautet: „Verfasse einen Einladungstext zu einer Online-Lehrveranstaltung über Zoom unter Einschluss folgender Vorgaben: Thema: XXX, Datum: XXX, Uhrzeit: XXX, Unterlagen zur Vorbereitung: XXX“ [submit], kein urheberechtlich geschütztes Werk.
Und ein mittels DALL·E 2 erzeugtes Bild auf Basis eines kurz gefassten Prompts wie etwa: „Paint a picture with several information security students with long hair eating a noodle soup containing noodles formed like a padlock!“ ist ebenfalls nicht urheberrechtlich geschützt.
![[Abbildung erzeugt mit DALL·E 2 auf Grundlage des o. g. Prompts]](https://blogs.hoou.de/lehredigital/wp-content/uploads/2023/04/Bild_erzeugt_mit_DALL·E-2_Studierende_Datensicherheit.png)
Ausnahmen können, wie oben aufgezeigt, gelten, wenn KI-generierte Erzeugnisse von Menschen nicht unerheblich weiterentwickelt oder bearbeitet werden – vorausgesetzt, diese bearbeitende Tätigkeit erreicht ein Mindestmaß an Originalität (siehe auch Kreutzer). Auf diese Weise kann ein urheberrechtlich geschütztes Werk entstehen; Urheber:in ist dann die Person, die die Anwendung nutzt. Anschauliches Beispiel hierfür ist der sog. AI Song Contest, zu dem eine der Beteiligten berichtet: „Man kann mithilfe von KI zwar Melodiesequenzen oder musikalische Ideen entwickeln, aber es braucht immer Menschen, um daraus ein richtiges Lied zu machen“.
Dasselbe gilt, wenn der Einfluss eines Menschen auf ein erzieltes Ergebnis so bestimmend ist, dass dieses der Person noch zugerechnet werden kann, wenn also der menschliche Anteil so hoch ist, dass der Einsatz des KI-Modells eine eher untergeordnete Bedeutung hat (siehe Lauber-Rönsberg und Ulbricht). Ein Beispiel hierfür ist ein von einem/einer Lehrenden verfasstes Skript, das die KI auf Grundlage bestimmter Eingaben nur moderat „überarbeitet“, kürzt oder den Stil lediglich geringfügig anpasst.
Viel spricht auch für die Annahme, dass die Eingabe besonders origineller Prompts und anschließende Weiterentwicklung eines KI-generierten Erzeugnisses mittels ergänzender Prompts zu einer Schutzfähigkeit des KI-Outputs führen kann. So könnte, wer sehr originelle Eingaben macht und einen generierten Text oder ein generiertes Bild in einem iterativen Prozess detailliert durch die Anwendung weiter anpassen lässt, im Einzelfall als Nutzer:in gegebenenfalls ein Urheberrecht erlangen (siehe Hoeren (S. 26) mit weiteren Nachweisen).
In diesem Fall ähneln Dienste wie die von OpenAI einem technischen Hilfsmittel wie einem Pinsel oder Schnitzeisen, das ein Mensch dazu nutzt, ein Werk nach seinen ganz konkreten Vorstellungen zu gestalten. Dies ist sowohl für Text- als auch Bildgeneratoren denkbar (und auch im Bereich Code, Musik (vgl. AI Song Contest) etc.) – dürfte, zumindest nach gegenwärtiger Einschätzung, vermutlich noch die Ausnahme sein, perspektivisch aber zunehmen.
Die Grenzen sind fließend. Es bleibt abzuwarten, wie die Rechtsprechung künftige Fälle bewerten und welche Kriterien sie für die Abgrenzung heranziehen wird.
Derzeit unwahrscheinlich ist die Annahme eines Schutzes von KI-Output durch die bestehenden sog. Leistungsschutzrechte. Diese setzen zwar keinen schöpferischen Akt voraus, sondern schützen nur die rein technische Leistung. So könnten KI-generierte Musikstücke dem Leistungsschutzrecht des Tonträgerherstellers unterliegen oder KI-generierte Nachrichtentexte dem sog. Leistungsschutzrecht für Presseverleger. Ein Schutz setzt aber auch eine gewisse Hoheit des KI-Anbieters über den Entstehungsprozess voraus, der eher nicht anzunehmen ist. Gut möglich ist jedoch, dass der Gesetzgeber im Urheberrechtsgesetz den Katalog der Leistungsschutzrechte in Bezug auf KI-Erzeugnisse anpassen bzw. erweitern wird.
Unter Berücksichtigung der Tatsache, dass das sog. Prompt Engineering allgemein inzwischen als eine der zentralen Kompetenzen der Zukunft angesehen wird, ist mit Spannung zu erwarten, inwieweit Prompts für sich genommen von den Gerichten als urheberrechtsfähig anerkannt werden (vgl. auch Jaeger) oder durch andere Schutzrechte geschützt werden.
2. Wie wirkt es sich aus, dass ein Großteil des KI-Trainingskorpus sich aus urheberrechtlich geschützten Werken und Materialien zusammensetzt?
Die Beantwortung dieser Frage ist stark abhängig vom gewählten Prompt. Zumindest bislang bestehen kaum Anhaltspunkte dafür, dass auf Anfrage als KI-Output Kopien von Originalen generiert und diese unzulässig vervielfältigt werden. Vielmehr entstehen in der Regel völlig neu zusammengesetzte Ergebnisse, die dann genutzt werden können.
Ist ein Prompt hingegen ausnahmsweise so formuliert, dass der Output des Textgenerators in nicht unerheblichem Ausmaß fremdes urheberrechtlich geschütztes Material wiedergibt, und werden anschließend der Output oder relevante Teile daraus neu im Internet veröffentlicht oder auf andere Weise genutzt, etwa verbreitet, kann dies eine Urheberrechtsverletzung sein. Bei Output von Bildgeneratoren ist die Situation anders – vorausgesetzt, dass nicht gezielt fremde Originale hochgeladen und weiterbearbeitet werden.
Hintergrund für – derzeit noch selten – mögliche Urheberrechtsverletzungen ist, dass z. B. bei ChatGPT die Trainingsdaten aus einer großen Menge an urheber- oder leistungsschutzrechtlich geschütztem Material bestehen. Dieses stammt, zumindest bei ChatGPT-3.5, aus unzähligen Online-Quellen, etwa Presseartikeln, E-Books, E-Paper, Wikis, öffentlich zugänglichen Inhalten von Websites und Blogs etc. Auch beim Bildgenerator DALL·E2 stammt das Bildmaterial im Trainingsfundus aus öffentlich zugänglichen Bildquellen und ist in aller Regel urheberrechtlich geschützt. Nutzungserlaubnisse wurden, soweit bekannt, nicht eingeholt. (Bei Diensten wie Llama von Meta ist immerhin genau offengelegt, zu wieviel Prozent welche Quelle verwendet wurde.)
Das sog. Text und Data Mining (TDM) ist grundsätzlich gesetzlich erlaubt, siehe § 44b UrhG.

Ferner gibt es zu Zwecken wissenschaftlicher Forschung die Spezialregelung des § 60d UrhG.

Beide Erlaubnisse regeln aber nur die Analyse von Werken. Eine Weiternutzung KI-generierten Outputs, etwa im Internet oder in wissenschaftlichen Zeitschriften, ist darin nicht geregelt, und die Kopien geschützter Werke sind nach Wegfall der Erforderlichkeit zu löschen.
Da es aber möglich ist, ChatGPT in einem Prompt beispielsweise zur Wiedergabe von Textauszügen, auch längeren Passagen, auch aus noch nicht gemeinfreien Büchern, Zeitungen und sonstigen Veröffentlichungen zu veranlassen – ohne dass die Rechteinhaber:innen hiervon Kenntnis bekommen und ihr Einverständnis erklärt haben, kann die nicht rein private oder durch gesetzliche Erlaubnisse abgedeckte Weiternutzung fremde Urheberrechte verletzen.
Beispielsweise können mit einer Eingabe wie folgt: „Zeige mir den Anfang des Romans von XY.“ neben sog. halluzinierten, also frei erfundenen, Textpassagen auch längere Original-Auszüge ausgegeben werden. Eine Zulässigkeit ist dann allenfalls auf Grundlage der Zitierfreiheit denkbar, was jedoch u. a. die inhaltliche Befassung mit dem Zitierten und eine Quellenangabe voraussetzt, § 51 UrhG.

Bei Bildern gilt: Bezüglich der Erstellung bzw. einer eventuellen Veröffentlichung eines entlehnten KI-Bildes kommt es darauf an, ob es sich hierbei um eine Bearbeitung bzw. Umgestaltung eines Originals im Sinne von § 23 Abs. 1 UrhG handelt oder ob das KI-Bild – was die Regel sein dürfte – einen hinreichenden Abstand zum ursprünglichen Werk aufweist.
Dies ist beispielsweise häufig in Fällen des sog. Outpaintings anzunehmen, bei denen Anwender:innen ein Bild oder Bilddetail über seine ursprünglichen Grenzen hinaus fortsetzen, bestimmte visuelle Elemente im gleichen Stil hinzufügen oder eine Geschichte in neue Richtungen lenken.

Es kommt bei der Beurteilung nicht darauf an, dass die durch DALL·E erzeugten Bilder keine zusammengesetzten Kopien von Einzelbestandteilen aus dem Trainingsfundus, sondern vielmehr völlig neu erzeugte Text-to-Image-Ergebnisse sind. Kern der Beurteilung möglicher Urheberrechtsverletzungen ist der Vergleich dessen, was am Ende wahrnehmbar ist, also die Gestaltung des Originals und die des KI-Outputs, d. h. dem auf Grundlage eines Prompts erzeugten Bildes als Ergebnis. Irrelevant ist, wie dieses erzeugt wurde. Bei aus Prompts erzeugten Bildern ist die Wahrscheinlichkeit, dass „Kopien“ erzeugt werden, derzeit noch sehr gering. Es ist allerdings ungewiss, in welcher Schnelligkeit neue Entwicklungen ganz andere Ergebnisse erzielen werden.
3. Darf KI-generierter Output in Lehrmaterialien oder Hausarbeiten genutzt werden?
Nach den Ausführungen unter 1. liegt in der Regel entweder kein Urheberrechtsschutz vor, mit der Folge, dass ein Ergebnis frei genutzt werden kann, oder die Rechte liegen bei dem/der Anwender:in. Dann kann diese:r frei darüber verfügen oder bei Bedarf anderen Nutzungsrechte erteilen.
Die Terms of Use von OpenAI sehen ebenfalls vor, dass die Anwendenden den KI-Output frei nutzen können, hierzu unter 3.:
As between the parties and to the extent permitted by applicable law, you own all Input, and subject to your compliance with these Terms, OpenAI hereby assigns to you all its right, title, and interest in and to Output. This means you can use Content for any purpose, including commercial purposes such as sale or publication, if you comply with these Terms. (zuletzt abgerufen am 05.04.2023)
Quellen- bzw. Bildangaben sind dann urheberrechtlich nicht erforderlich, zwecks Klarstellung aber hilfreich, und zudem von einigen Diensten laut Nutzungsbedingungen wiederum vorgegeben.
(Beispielformulierung: Abbildung erzeugt mit DALL·E, prompted by Vorname/Nachname Anwender:in)
Ausnahmen können gelten, wenn der nachgenutzte KI-Output ganz oder in nicht unerheblichen Teilen aus noch geschützten Werken oder Materialien Dritter besteht (siehe Erläuterungen unter 2.).
Eine Zulässigkeit kann dann nur, wenn eine eigene Befassung mit dem Zitierten stattfindet, auf Basis der Zitierfreiheit, § 51 UrhG, oder der gesetzlichen Erlaubnisse zugunsten von Unterricht und Lehre gegeben sein – vorausgesetzt, die Rahmenbedingungen sind jeweils vollständig erfüllt, bei § 60a UrhG u. a. eine Nutzung zwecks Veranschaulichung der Lehrinhalte und eine Quellenangabe.
4. Ist es urheberrechtlich zulässig, ein Werk „im Stil von (Künstler:in/Fotograf:in XY)“ zu generieren und weiter zu verwenden, z. B. in einem Skript oder in einer Hausarbeit?
Einzelfälle und künftige Rechtsprechung hierzu sind abzuwarten, aber grundsätzlich gilt: Ein Stil ist nach dem deutschen Urheberrecht nicht schutzfähig. Daher spricht sehr viel dafür, dass ein solches Vorgehen zulässig ist. Auch können, je nach Einzelfall, Nutzungen nach der neuen Regelung des § 51a UrhG zum sog. Pastiche zulässig sein, die Vervielfältigungen zum Zwecke der Nachahmung eines Stils oder einer Idee erlaubt – sofern eine Auseinandersetzung mit dem vorbestehenden Werk stattfindet.
Das hat zur Konsequenz, dass ein/e Künstler:in oder Fotograf:in nach deutschem Urheberrecht nicht dagegen vorgehen könnte, wenn ein KI-basierter Bildgenerator auf Grundlage eines Prompts Arbeiten in seinem bzw. ihrem Stil erzeugt und diese weiterverwendet werden. Die Bewertung fiele anders aus, wenn das KI-Erzeugnis, beispielsweise ein Bild, eine 1:1-Kopie oder allenfalls geringfügige Abwandlung eines Originals ergeben und diese verwendet würde (siehe Lauber-Rönsberg).
Eine Zulässigkeit käme dann auch wieder nur bei Vorliegen der Voraussetzungen der Zitierfreiheit, § 51 UrhG, oder der Erlaubnisse zugunsten von Unterricht und Lehre, § 60a UrhG, in Betracht.
5. Wie kennzeichne ich als Lehrende:r oder Studierende:r eigene KI-generierte Erzeugnisse in meinen Materialien/Arbeiten, wie zitiere ich fremde KI-generierte Erzeugnisse, und wie gehe ich hinsichtlich der Hilfsmittelangabe vor?
Noch gibt es keine gefestigten Standards zur Kennzeichnung und Zitierweise.
Es kommen in Betracht:
- die Angabe der verwendeten KI*, ggf. ergänzt um
- die wortwörtliche Wiedergabe des verwendeten Prompts, und/oder ergänzt um
- die Namensbezeichnung, d. h. Vor-/Nachname oder Pseudonym der die KI anwendenden Person, ggf. ergänzt um
- eine Angabe zur Form bzw. Art der Bearbeitung
- und (sofern vorhanden) eine Quellenangabe*.
*(Dies ist teils durch die Nutzungsbedingungen auch so vorgegeben.)
Die Umsetzbarkeit oder Eignung der vorgeschlagenen Angaben ist abhängig von:
- dem Einsatzszenario,
- der Länge oder Komplexität des verwendeten Prompts,
- der Art des KI-Outputs (Text, Bild, Code etc.) sowie
- einer eventuellen Bearbeitung oder Umgestaltung.
Ist bei der Erledigung studentischer Arbeiten der Einsatz generativer KI gestattet bzw. nicht explizit ausgeschlossen, so sind Vorgaben, die der/die Lehrende zur Art und Weise der Kennzeichnung der Nutzung gegebenenfalls gemacht hat, zu beachten.
Gibt es keine spezifischen Vorgaben, so empfiehlt es sich, bei der Übersicht der verwendeten Hilfsmittel die eingesetzte KI-Anwendung mit anzugeben – einerseits technisch (Bezeichnung genutztes Tool), andererseits fachlich-methodisch.
Hoeren (S.29) schlägt zur Hilfsmittelangabe noch folgende Differenzierung vor: „Wurde das KI-Programm […] als Inspirationsquelle oder Gedankenanstoß verwendet, könnte eine Hilfsmittelangabe zu Beginn oder am Ende genügen. Eine Hilfsmittelangabe dürfte auch für den Fall genügen, dass der KI-generierte Text wortwörtlich übernommen wird, nachdem die Nutzer:in wie oben beschrieben den prompt so formuliert hat, dass die KI keinen Zufallsspielraum mehr hat bzw. die Eingabe durch konkretisierende prompts der Nutzer:in soweit präzisiert wurden, dass ein Urheberrecht für die Nutzer:in wieder angenommen werden kann“.
*Anmerkung: Möchte man ein KI-Erzeugnis zitieren oder als OER nutzen und hierfür die Quelle angeben, kommt anstelle eines originären Links nur die Angabe der Fundstelle, an der das KI-Erzeugnis erstmals durch den/die Anwender:in veröffentlicht wurde (falls dies überhaupt der Fall ist), in Frage, da ein späteres Abrufen der Ursprungsquelle für andere als diese Person nicht möglich (bzw. ohnehin auch für diese ggf. nicht dauerhaft möglich ist).
Für Lehrende kann es je nach Fachrichtung empfehlenswert sein, bei Bedarf die bei Hausarbeiten übliche Eigenständigkeitserklärung um Hinweise zu Schreib- oder Bildgeneratoren zu ergänzen, wie etwa im Muster von Weßels:

Nicht empfehlenswert ist es, ChatGPT oder eine vergleichbare Anwendung, die als Schreib- oder Kreativhilfe eingesetzt wurde, als Co-Autor:in oder Miturheber:in anzugeben, da die KI-Anwendung rein rechtlich hierfür ausscheidet.
6. Ist KI-Output OER-fähig, d. h. kann er als Open Educational Resource frei zur Nachnutzung lizenziert werden?
Als OER, also offene Bildungsressource, können nur Materialien lizenziert werden, für die ein Urheberrechtsschutz grundsätzlich in Frage kommt, d. h. für persönliche geistige Schöpfungen. Da ein Urheberrechtsschutz bei KI-Output nur in Ausnahmefällen anzunehmen ist, und zwar in erster Linie wenn der kreative Anteil eines Menschen prägend für das Gesamtergebnis ist (siehe unter 1.), ist auch nur für diese Fälle eine OER-Lizenzierung grundsätzlich denkbar.
Sie ist zwecks Vermeidung von Haftungsrisiken allerdings nicht immer empfehlenswert. Dies liegt daran, dass Anwender:innen nicht (immer) erkennen können, ob und inwieweit urheberrechtlich geschütztes Material oder urheberrechtlich geschützter Text, Code etc. Bestandteil des KI-Outputs ist, das lizenziert werden soll. Daher könnte eine Vervielfältigung, Verbreitung, öffentliche Zugänglichmachung im Internet oder ähnliche Nutzung der entsprechenden Materialien als OER risikobehaftet sein (siehe Hoeren (S. 30)).
Nicht ausgeschlossen ist es, KI-Output, sofern er in Ausnahmefällen als urheberrechtlich geschützt anzusehen ist, innerhalb einer OER im Wege eines Zitats zu nutzen – sofern die allgemeinen Voraussetzungen hierfür vorliegen, insbesondere eine inhaltliche Befassung mit dem Zitierten.
Für Fälle, in denen der Inhalt des KI-Outputs urheberrechtlich unbedenklich erscheint, ist eine Nutzung innerhalb einer OER möglich, eine Lizenzvergabe hingegen aus oben genannten Gründen rechtlich nicht erforderlich.
7. Worauf muss ich achten, wenn ich Texte, Fotos, Bilder etc. im Zuge einer Eingabe in die KI-Dienste einspeise?
Durch die Eingaben dürfen keine Rechte Dritter verletzt werden. Die Versuchung, bei KI-gesteuerten Text- oder Bildgeneratoren bestimmte Eingaben auszuprobieren oder sich mittels der Dienste die Arbeit zu erleichtern, ist sehr groß. Nutzende müssen jedoch im Blick haben, über die erforderlichen Rechte an allem, was sie eingeben oder hochladen, zu verfügen.
Beachten sie dies nicht, können Eingaben oder Uploads zu Verstößen führen gegen:
- Urheberrechte und andere Bestimmungen aus dem Urheberrechtsgesetz;
- Persönlichkeitsrechte (u. a. das Recht am eigenen Bild + das informationelle Selbstbestimmungsrecht);
- datenschutzrechtliche Bestimmungen;
- Vertraulichkeitsvereinbarungen;
- Sorgfaltspflichten im Arbeitsverhältnis und/oder
- die Nutzungsbedingungen der Dienste
und in Einzelfällen unter Umständen sogar strafrechtliche Konsequenzen haben.
Das bedeutet, dass beispielsweise der Upload von Personenfotos oder die Eingabe sensibler Daten oder Informationen über Personen mit ausführlichen biografischen Angaben, die nicht ohnehin schon rechtmäßig öffentlich verfügbar gemacht sind, in der Regel ohne Einwilligung unzulässig sind – sofern nicht eine Ausnahmevorschrift gemäß KUG oder DSGVO greift. Eine Ausnahme kann etwa vorliegen bei Bildnissen, in denen Personen eher als Beiwerk vorkommen, oder aus dem Bereich der Zeitgeschichte, bei Fotos von bekannten Amtsträger:innen bei Wahrnehmung ihrer Dienstgeschäfte. Ein Grenzfall, aber mutmaßlich noch zulässig, ist das Beispiel des KI-generierten Fotos mit Papst Franziskus im weißen Daunenmantel.
Der Schutz von Rechten Dritter ist insbesondere vor dem Hintergrund, dass Chat-Eingaben und hochgeladenes Material im Falle von OpenAI von den Mitarbeitenden eingesehen werden können, keine konkreten Angaben zu Speicherfristen gemacht werden und Löschungsansprüche in der Praxis schwer umsetzbar sein dürften, besonders virulent.
Siehe hierzu die FAQ von OpenAI (unter 5.):
- Who can view my conversations?
- As part of our commitment to safe and responsible AI, we review conversations to improve our systems and to ensure the content complies with our policies and safety requirements.
Eigene Texte und selbst angefertigte Fotos, Grafiken, Sounds etc., in denen keine Personen vorkommen, dürften in aller Regel unproblematisch sein, ebenso Gemeinfreies, d. h. solche Materialien, bei denen die urheberrechtliche Schutzdauer abgelaufen ist oder ein Schutz gar nicht erst besteht.
8. Stichwort Datenschutz: Welche Daten von Nutzenden werden bei Nutzung der Text-/Bildgeneratoren verarbeitet?
Das kann sehr unterschiedlich sein und hängt stark vom jeweiligen KI-Dienst ab. Bei den Diensten von OpenAI ist der Umfang der Datenverarbeitung zudem, Stand: Ende Anfang April 2023, davon abhängig, ob die kostenfreie Basis- oder die Bezahlvariante genutzt wird.
Im Zuge der Registrierung für die kostenfreie Nutzung von ChatGPT & Co. werden die E-Mail-Adresse und die Mobilnummer der Nutzenden abgefragt, für die kostenpflichtige Variante weitere Angaben, u. a. Bezahldaten.
Neben Registrierungs-/Anmeldedaten werden u. a. Logfiles, die bei Nutzung der Anwendung gespeichert werden, sowie die Inhalte der jeweiligen Eingabe (d. h. sämtliche Daten, Texte, Bilder etc., die die Nutzenden im Zuge eines Prompts eingeben bzw. hochladen) verarbeitet.
Die Eingabetexte können von OpenAI unter anderem zur Weiterentwicklung der Dienste und zur Sicherheitszwecken genutzt werden, siehe hierzu die FAQ:
- Will you use my conversations for training?
Yes. Your conversations may be reviewed by our AI trainers to improve our systems.
Datensparsamer gegenüber individuellen Registrierungen der Lehrenden und Studierenden – wenngleich mit Programmieraufwand und Kosten verbunden – sind, beispielsweise von OpenAI, Schnittstellen-Lösungen für Hochschulen für deren digitale Lernumgebungen. Diese ermöglichen zumindest pseudonyme Nutzungen und können, je nach Ausgestaltung, auch regelmäßige Löschungen der bei Nutzung der Dienste verarbeiteten Daten vorsehen, z. B. im 24-h-Rhythmus (so beispielhaft für den Schulunterricht der Anbieter fobizz).
Auch für das Lernmanagementsystem Moodle existiert bereits ein kostenloses Plugin, mit dem OpenAI Chat-Sprachmodelle angebunden werden können. Ebenfalls bietet OpenAI eine Dokumentation, wie Nutzende eigene Plugins entwickeln können.
Die Nutzungsbedingungen von OpenAI differenzieren bei den Informationen zur Datenverarbeitung danach, ob die zur Verfügung gestellte Schnittstelle (API) für Eingaben genutzt wird oder nicht (siehe hierzu unter 3., bei der Angabe der Nutzungszwecke):
(c) Use of Content to Improve Services. We do not use Content that you provide to or receive from our API (“API Content”) to develop or improve our Services. We may use Content from Services other than our API (“Non-API Content”) to help develop and improve our Services.
Details zur Datenverarbeitung sind der Privacy Policy des genutzten Dienstes zu entnehmen, siehe beispielsweise für OpenAI hier.
9. Auf welche Rechtsgrundlage lässt sich der Einsatz von KI-Diensten wie ChatGPT in der Hochschullehre stützen?
Auf diese Frage gibt es mit Hinblick auf die bisherige Ausgestaltung der meisten Angebote bislang nur unbefriedigende Antworten. Erste Verbote von ChatGPT, wie etwa in Italien, die sich neben anderen Aspekten auch auf eine fehlende Rechtsgrundlage stützen, machen die Brisanz auch für Deutschland deutlich. Auch in Deutschland werden Sperrungen zumindest diskutiert.
Grundsätzlich gilt: Der Einsatz von KI-Anwendungen in der Lehre darf grundsätzlich nur unter Einhaltung geltender datenschutzrechtlicher Bestimmungen, insbesondere unter Beachtung der in Art. 5 DSGVO festgelegten Grundsätze für die Verarbeitung personenbezogener Daten erfolgen, die die Säulen der DSGVO bilden. Dazu zählt gemäß Art. 5 Abs. 1 lit. a DSGVO auch, dass die Nutzung rechtmäßig erfolgen, d. h. eine Rechtsgrundlage vorliegen muss, die die Datenverarbeitung an der Hochschule erlaubt.
Viele Anbieter von KI-Anwendungen haben ihren Sitz und ihre Server in den USA und erfüllen derzeit nicht die Datenschutzstandards der DSGVO. An Hochschulen kommt derzeit allenfalls eine freiwillige Nutzung auf Basis einer informierten Einwilligung gemäß Art. 6 Abs. 1 S. 1 lit. a DSGVO in Frage. Das heißt auch: Studierende dürfen im Rahmen von Lehrveranstaltungen von Lehrenden nicht zur Nutzung, insbesondere nicht zur Registrierung, verpflichtet werden.
Informierte Einwilligungen der Studierenden setzen jedoch auch voraus, dass diese die Gelegenheit haben, transparente Datenschutzhinweise zur Kenntnis zu nehmen, und sie eine echte Alternative angeboten bekommen, z. B. die Nutzung eines alternativen datenschutzkonformen KI-Dienstes aus Deutschland bzw. zumindest dem EU-Raum oder etwa die Teilnahme an einem geeigneten Alternativseminar. Aber auch die Einwilligung als Rechtsgrundlage ist rechtsdogmatisch zweifelhaft, wird sie doch von gewichtigen Stimmen in der Rechtsliteratur als ungeeignetes oder gar rechtswidriges Instrument gesehen, da Einwilligende in Fällen einer häufig übereilten Einwilligungserklärung letztlich gar keine Kenntnis bzw. kein echtes Bewusstsein hätten, in was sie eigentlich einwilligen.
Weitere Rechtsgrundlage, die in theoretisch Frage kommt, sind die sog. berechtigten Interessen, Art. 6 Abs. 1 S. 1 lit. f DSGVO – die aber wiederum zumindest für staatliche Hochschulen von vornherein ausscheiden.
Empfehlenswert, wenn auch keine echte Lösung in diesem Zusammenhang, ist der Rückgriff auf Schnittstellen bzw. Plugins (siehe unter 8.), die zumindest eine pseudonyme Nutzung ermöglichen, so dass personenbezogene Daten nur eingeschränkt verarbeitet werden, oder, wenn auch praxisfern, die Nutzung einzig über den Zugang der Lehrperson.
Im Übrigen bleibt zu hoffen, dass sich vermehrt Anbieter mit Servern im EU-Raum etablieren (wie etwa Aleph Alpha), die das reale Anliegen haben, die gesetzlichen Anforderungen des Datenschutzes ernsthaft anzugehen.
10. Welche datenschutzrechtlichen Verpflichtungen kommen auf Hochschulen bei Nutzung generativer KI-Modelle zu?
Hinsichtlich des Datenschutzes bei Einsatz von KI-Diensten, bestehen die üblichen Handlungsbedarfe wie bei sonstigen digitalen Diensten und Anwendungen auch, die an Hochschulen zu Lehrzwecken eingesetzt personenbezogene Daten verarbeiten.
⇒ Siehe hierzu auch den Blogbeitrag Digitale Tools an Hochschulen – mit dem Datenschutz im Blick… (inkl. 4-seitiger-Checkliste zur Auftragsverarbeitung).
Die Umsetzung der datenschutzrechtlichen Anforderungen stellt die Hochschulen, u. a. aufgrund fehlender Transparenz der Anbieter bezüglich der Datenverarbeitungen, vor große Herausforderungen.
Zu den wichtigsten Maßnahmen zählen gleichwohl:
- die Vornahme einer allgemeinen Datenschutzprüfung inkl. Prüfung der DSGVO-Konformität der technischen und organisatorischen Maßnahmen (sog. TOMs), die die Sicherheit der Verarbeitung personenbezogener Daten gewährleisten sollen (Bsp.: Sicherstellung von Schutzmaßnahmen gegen den Zugriff Dritter);
- die Überprüfung des Vorliegens einer Rechtsgrundlage, die die Nutzung zu Lehrzwecken gestattet;
- (i.d.R.) der Abschluss eines Auftragsverarbeitungsvertrages (oder, je nach Konstellation, einer Vereinbarung über die gemeinsame Verantwortlichkeit), inkl. Prüfung bereitgestellter Vertragsmuster oder Erarbeitung eigener Verträge;
- das Verfassen und Bereitstellen von Datenschutzhinweisen für die Nutzung (inklusive – aber nicht ausschließlich – durch Link zur ‚Privacy Policy‘ auf den Anbieter-Websites);
- die Dokumentation aller oben genannten Schritte und Vertragsunterlagen im sog. Verzeichnis von Verarbeitungstätigkeiten, inklusive regelmäßiger Reviews.
Mit Hinblick auf mögliche Risiken für die Rechte und Freiheiten betroffener Personen durch Datenverarbeitungen im Zuge der KI-Nutzung in der Lehre, spricht außerdem viel für das Erfordernis der Vornahme und Dokumentation einer sog. Datenschutzfolgeabschätzung i. S. v. Art. 35 DSGVO. Dabei handelt es sich um eine Risikobewertung, innerhalb derer geprüft und eine Einschätzung gegeben wird, welche Folgen die Verarbeitung personenbezogener Daten im Zuge der Nutzung des gewählten KI-Dienstes für den Schutz der Daten der hiervon Betroffenen haben kann.
Fazit
Der Einsatz KI-basierter Text- und Bildgeneratoren sowie ähnlicher Systeme birgt für die Hochschullehre einen hohen Mehrwert, Arbeitserleichterung auf vielen Ebenen – und schier unendliche Chancen und Potenziale. Die rechtliche Einordung ist in vielen Punkten indes noch ungeklärt. Vor allem im Urheberrecht stellen sich komplizierte Abgrenzungsfragen, und im Datenschutz gilt es, bislang noch kaum lösbare Hürden zu nehmen.
Aufgrund potenzieller Urheber- und Persönlichkeitsrechtsverletzungen sowie Datenschutzverstöße besteht ein hoher rechtlicher Regelungsbedarf – seitens der Gesetzgeber auf EU- und nationaler Ebene ebenso wie unmittelbar an den Hochschulen (Satzungsrecht). In den bislang diskutierten Entwürfen der geplanten EU-Verordnung zur künstlichen Intelligenz war generative KI wie Chatbots bislang nicht detailliert vorgesehen; aktuell wird daher mit Hinblick auf die hohe Relevanz und Aktualität diskutiert, wie sich diese Techniken noch kurzfristig angemessen in die Regulierung einbinden lassen. Selbst wenn dies zeitnah erfolgen sollte, ist jedoch frühestens 2024 mit einem Inkrafttreten der EU-Regelungen zu rechnen. Und es wird dann keine Überraschung sein, wenn die neuesten technischen Entwicklungen den in schwierigen Abstimmungsprozessen getroffenen gesetzlichen Regelungen erneut Riesenschritte voraus sein werden.
Ungeachtet dessen gilt: Auch wenn derzeit allerorten Text-, Bildgeneratoren und andere Anwendungen getestet werden und der Einsatz von KI-Modellen für viele Hochschulangehörige seit geraumer Zeit bereits nicht mehr wegzudenken ist, ist jede/r Einzelne gehalten, die Dienste bewusst und verantwortungsvoll zu nutzen, fremde Rechte dabei stets im Blick zu haben – und KI-Output vor Weiternutzung auch immer kritisch zu hinterfragen.
Die Hochschulen in ihrer Rolle als datenschutzrechtliche Verantwortliche wiederum sind allein aus rechtsstaatlichen Gründen in der Pflicht, entstandenen Wildwuchs an ihren Einrichtungen einzufangen und – allen Hindernissen zum Trotz – möglichst schnell Prozesse zur Umsetzung datenschutzrechtlicher Vorgaben zu initiieren. Dies bedingt aber auch die Möglichkeit einer Auswahl zwischen Anbietern, die bei ihren KI-Entwicklungen die Prinzipien ‚Privacy by Design‘ und ‚Privacy by Default‘ deutlich stärker als bislang mitdenken und umsetzen.
Weiterführende Quellen:
- Didaktische und rechtliche Perspektiven auf KI-gestütztes Schreiben in der Hochschulbildung
(3/2023, Hg.: Leschke, J., Salden, P.; Veröffentlichung via Ruhr-Universität Bochum, Universitätsbibliothek), Rechtsgutachten ab S. 22 (Hoeren, T.)
https://doi.org/10.13154/294-9734 - ChatGPT: Risks and challenges from a Data Privacy perspective (14.03.2023, Suarez, T. V. E.)
Blogbeitrag auf datenschutz-notizen.de, Blog von datenschutz nord - AI-mazing: DALL-E und ChatGPT malen ein Bild der Zukunft
Überblick zu den rechtlichen Problemen bei der Verwendung von KI-Software (John, N.)
DFN Infobrief Recht 3/2023, S. 2 - KI in Unternehmen. Ein Praxisleitfaden zu rechtlichen Fragen
(2/2021, Kreutzer, T, Christiansen, P.)
https://www.bertelsmann-stiftung.de/fileadmin/files/user_upload/KI_in_UN.pdf - Künstliche Intelligenz: Kampf um das Urheberrecht
(17.02.2023, Jaeger, T.)
Blogbeitrag auf heise.de - Prüfungsrechtliche Fragen zu ChatGPT
(21.02.2023, Fleck, T, Stabsstelle IT-Recht der bayerischen staatlichen Universitäten und Hochschulen)
https://www.rz.uni-wuerzburg.de/fileadmin/42010000/2023/ChatGPT_und_Pruefungsrecht.pdf (offen lizenziert, CC BY-SA 4.0)
 Dieser Beitrag ist, mit Ausnahme der KI-Bilder und Zitate, lizenziert unter einer Creative Commons Namensnennung – Weitergabe unter gleichen Bedingungen 4.0 International Lizenz.
Dieser Beitrag ist, mit Ausnahme der KI-Bilder und Zitate, lizenziert unter einer Creative Commons Namensnennung – Weitergabe unter gleichen Bedingungen 4.0 International Lizenz.
Lizenzhinweis: „Urheberrecht und Datenschutz bei ChatGPT & Co. in der Hochschullehre„, Andrea Schlotfeldt | HOOU@HAW, CC BY SA 4.0