Curriculum
KISS* - KI für Schüler*innen und Studierende
Einführung
0/7KI - Technik und Anwendungen
0/20KI und Philosophie
0/3Materialien
0/13 Wie funktioniert KI?
 In diesem Abschnitt wollen wir uns damit beschäftigen, was das Besondere an der Künstlichen Intelligenz ist. Die Betonung des „Künstlichen“ in der KI verweist darauf, dass es auch eine nicht-künstliche Intelligenz gibt, also dass wir Intelligenz ursprünglich aus der Natur kennen. Werfen wir also zunächst einen Blick auf die natürliche Intelligenz.
In diesem Abschnitt wollen wir uns damit beschäftigen, was das Besondere an der Künstlichen Intelligenz ist. Die Betonung des „Künstlichen“ in der KI verweist darauf, dass es auch eine nicht-künstliche Intelligenz gibt, also dass wir Intelligenz ursprünglich aus der Natur kennen. Werfen wir also zunächst einen Blick auf die natürliche Intelligenz.
Selbstcheck: Überlege einmal selber, wo du aus der Natur (zum Beispiel bei Tieren) intelligentes Verhalten findest und was daran intelligent ist. Schreibe ein solches Beispiel auf und diskutiere es mit den anderen Kursteilnehmern.
Was heißt intelligent?
Eine Krähe, die Nüsse auf eine Straße fallen lässt, damit diese von den darüber fahrenden Autos geknackt wird; ein Affe, der einen Stock benutzt, um sich eine Frucht zu angeln, oder ein Vogel, der einen Smartphone-Klingelton nachsingt. Es gibt viele Verhaltensweisen, die wir als intelligent bezeichnen. Bei Tieren und Menschen scheinen einige der Verhaltensweisen bereits seit Geburt „einprogrammiert“, z.B. der Greifreflex oder das Erkennen des Gesichts oder der Stimme von Mutter und Vater. Anderes Verhalten wie das Auffangen eines Gegenstands, das Laufen auf zwei Beinen oder das Sprechen muss erst erlernt und geübt werden.
Warum eigentlich „Künstliche“ Intelligenz?
Wir haben einige Beispiele intelligenten Verhaltens bei Mensch und Tier betrachtet. In der Natur scheint eine gewisse Form von „natürlicher Intelligenz“ verbreitet zu sein. Sie sorgt dafür, dass Lebewesen etwas Neues lernen und nicht nur „einprogrammierte Verhaltensweisen“ abspulen. Lernen und Training scheinen besondere Merkmale von Intelligenz zu sein. Das Nachbauen dieser intelligenten Verhaltensweisen mit Computern oder Maschinen holt diese aus dem Bereich der Natur in den Bereich des Künstlichen.
Die Bedeutung des Lernens
Die Künstliche Intelligenz beschäftigt sich also mit der Frage, wie intelligentes Verhalten durch technische Verfahren oder Maschinen realisiert werden kann. Hierbei treffen wir auch auf eine spezielle Art des Lernens: das Maschinelle Lernen (engl. Machine Learning). Zur Charakterisierung dieser besonderen Form des Lernens wollen wir noch einmal unterscheiden zwischen Lernen im Sinne von Auswendiglernen und Lernen im Sinne von Trainieren. Viele Verhaltensweisen, die wir als intelligent bezeichnen, entstehen nicht durch einmaliges Auswendiglernen (wie Vokabeln oder das Einmaleins), sondern durch wiederholtes Ausprobieren und Verfeinern, wodurch das Ergebnis graduell immer besser wird. So brabbelt ein kleines Kind zunächst zusammenhanglose Laute, um dann in einem Monate und Jahre dauernden Prozess immer besser im Sprachgebrauch zu werden. Das geht so lange, bis es sich eigenständig der Sprache bedienen kann und schließlich sogar eigene Gedanken sprachlich formulieren kann. Man beachte beim Spracherwerb auch, dass das ständige Feedback und Korrigieren durch Erwachsene dem Kind hilft, die Sprache richtig zu lernen. Dieser Aspekt des korrigierenden Bewertens und Eingreifens ist auch beim Maschinellen Lernen eine wichtige Komponente und zu unterscheiden von einem reinen Abspeichern und Abfragen von Daten.
Wir halten also fest:
Intelligenz beruht auf der Möglichkeit, durch Lernen (im Sinne von Training) neue Fähigkeiten zu erlangen.
Bei der menschlichen Intelligenz kommen noch weitere intelligente Fähigkeiten hinzu, die durch einfaches Training nicht erklärbar sind. Abstraktes Wissen, logisches und mathematisches Denken finden wir in der Natur nur beim Menschen. Hier besteht noch sehr viel Forschungsbedarf für die KI.
Wie hat sich die Künstliche Intelligenz entwickelt?
Historisch gibt es drei Phasen in der KI, intelligentes Verhalten mit Maschinen zu realisieren.
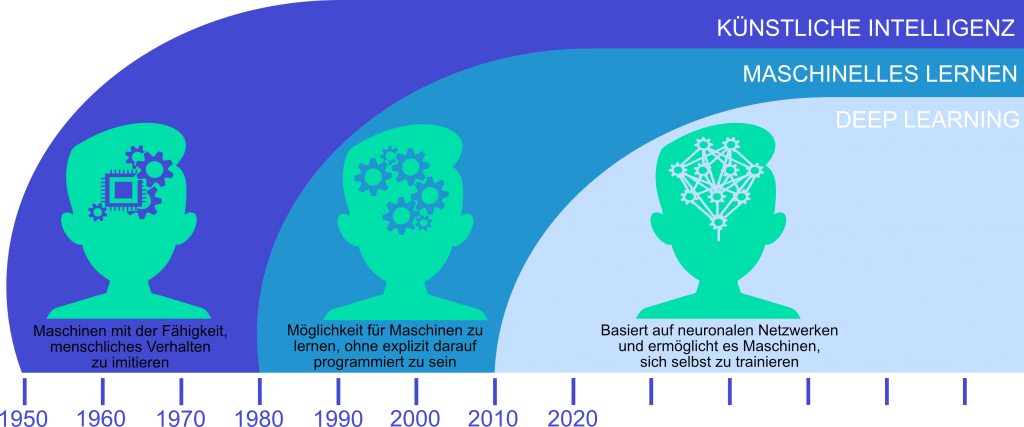
Phase 1 – In dieser Phase dachte man, komplizierte Berechnungen und das Beantworten von Wissensfragen seien typische Fälle von Intelligenz. Diese Form der KI beruht auf der Speicherung von Informationen und der Programmierung von festen Regeln. Da es sich hier um die Abarbeitung von vordefinierten Prozessen und Prozeduren handelt, kann man diese Phase als Prozedurale Phase der KI bezeichnen. Typische Beispiele dafür sind der Schachcomputer und Expertensysteme. In Kapitel 4 werden wir uns das an einem Expertensystem ansehen.
Phase 2 – Die zweite Phase der künstlichen Intelligenz macht sich den oben geschilderten Lern- oder Trainingsprozess zunutze. Statt alle Antworten fest in ein System aus Informationen und Regeln einzuprogrammieren, wird ein sogenanntes Modell durch Beispiele trainiert, sodass man damit Muster in den Daten erkennen kann. In dieser Stufe der KI wurden statistische Methoden eingeführt, um anstelle von sicheren Informationen (wie in Phase 1) auch unter unsicheren Gegebenheiten zu Ergebnissen zu kommen. Diese Phase kann man als die Frühe Phase des Maschinellen Lernens bezeichnen. In Kapitel 5 bis 10 lernen wir einige dieser Methoden kennen.
Phase 3 – Die dritte Phase der KI orientiert sind an biologischen Grundstrukturen. Die Neurobiologie hat festgestellt, dass biologische Nervensysteme und Gehirne ganz anders funktionieren als Computer. Es gibt keine fest einprogrammierten Regeln im Gehirn und auch keinen zentralen Speicher, wo unser ganzes Wissen abgelegt wird. Stattdessen entdeckte man überall da, wo in der Natur Informationen verarbeitet werden, mehr oder weniger komplexe Neuronale Netze:
Das sind komplizierte Geflechte aus Nervenzellen. In einem zweiten Schritt versuchte man dann, diese biologischen Strukturen nachzubauen oder zu simulieren, um die intelligenten Leistungen künstlich nachzuahmen. Da in diesen Modellen mehrere Stufen von Neuronalen Netzen hintereinandergeschaltet werden, spricht man hier auch von der Phase des Deep Learning. Im Kapitel 11 werden wir uns genauer mit diesen Künstlichen Neuronalen Netzen befassen.

Grundlegende Bausteine von Künstlicher Intelligenz
Wir haben nun einige wichtige Aspekte der Künstlichen Intelligenz aus den Eigenschaften natürlicher Intelligenz hergeleitet. Insbesondere sind das das Lernen als Training, aber auch die Idee, einmal die Funktionsweise des Gehirns anzuschauen.
Im Folgenden wollen wir uns mit ein paar Grundbegriffen der Künstlichen Intelligenz vertraut machen, die hier in allen Kapiteln und in allen KI-Verfahren immer wieder vorkommen bzw. wiederkehren werden. Gemeint sind vor allem drei Grundbegriffe:
Daten
Algorithmen
Modelle
3.1 Daten
Wir hören und lesen es allerorten: Daten sind das neue Öl.
Selbstcheck: Überlege einmal: Was bedeutet dieser Satz? Was will er aussagen? Wo fallen Daten an? Wie kommen wir an Daten heran? Warum sind Daten vielleicht wertvoll?
Schauen wir noch einmal auf unsere Liste aus dem ersten Kapitel.
Übung: Schau Dir die Liste aus dem ersten Kapitel an. Welche Eingabedaten und Ausgabedaten spielen bei den aufgelisteten KI-Services eine Rolle. Trage diese in die Spalte Eingabedaten und Ausgabedaten ein.
| KI-Service | Eingabedaten | Ausgabedaten |
| Smartwatch / Intelligenter Wecker
Schlafdatenauswertung |
Bewegung und Puls | „Guter Schlaf“/ „Schlechter Schlaf“ Weckzeit |
| Digital-Assistent (Alexa, Siri) | Gesprochene Aufforderung | Antwort oder Aktion |
| Gesichtserkennung und Fingerabdruckerkennung | Abbild des Gesichts oder eines Fingers | Identität der Nutzer*in |
| Posts bei Instagram | Bereits angeschaute Postings und Likes | Die nächsten Postings |
| Computerschach | Aktuelle Situation auf dem Brett | Nächster Zug |
| Email-Spamfilter | Bereits erhaltene Mails | Spam / Nicht Spam |
| Staubsauger-Roboter | Aktueller Ort und Gesamtsituation | Nächster Bewegung |
| Wetterprognose | Historische Wetterdaten | Wetterprognose |
| Optimale Routenplanung | Ort und Situation | Routenbeschreibung |
| Selbstfahrendes Auto | Sensordaten (Kamera, Radar), GPS und Maps | Links, rechts, Gas geben, Bremsen |
| Nächster Songvorschlag | Bereits gehörter Songs und Likes | Nächster Song |
| Dienst (Musik Erkennung) | Audioaufnahme durch Mikrofon | Titel und Interpret |
| Textergänzung | Bereits eingegebner Text | Nächste Wörter |
| Objekterkennung/Artenbestimmung | Einprogrammierte Daten und Regeln und aktuelle Daten | Vogelart |
| Vogelgesang -App | Audioaufnahme durch Mikrofon | Vogelart |
Es ist wichtig zu wissen, dass vieles, was zunächst nicht sofort als Daten erkennbar ist, durch die Digitalisierung in Daten umgewandelt werden kann. Gemeint sind z.B. Bilder, menschliche Sprache, Musik oder Vogelgesang. Wie das geht, kann man links sehen. Aus dem Abbild eines „A“ auf einem Bild wird zunächst ein Raster aus schwarz-weißen Punkten, dann werden die Punkte in Zahlen umgewandelt, wobei hier schwarze Punkte als 1 und weiße Punkte als 0 kodiert werden. Je feiner das Raster wird, desto exakter kann das Bild umgewandelt werden. Wenn man nicht nur 1 und 0 verwendet, kann man auch Farben in Zahlen kodieren. Dieses Prinzip finden wir in Scannern, digitalen Fotoapparaten und in unseren Smartphone-Kameras.
erkennbar ist, durch die Digitalisierung in Daten umgewandelt werden kann. Gemeint sind z.B. Bilder, menschliche Sprache, Musik oder Vogelgesang. Wie das geht, kann man links sehen. Aus dem Abbild eines „A“ auf einem Bild wird zunächst ein Raster aus schwarz-weißen Punkten, dann werden die Punkte in Zahlen umgewandelt, wobei hier schwarze Punkte als 1 und weiße Punkte als 0 kodiert werden. Je feiner das Raster wird, desto exakter kann das Bild umgewandelt werden. Wenn man nicht nur 1 und 0 verwendet, kann man auch Farben in Zahlen kodieren. Dieses Prinzip finden wir in Scannern, digitalen Fotoapparaten und in unseren Smartphone-Kameras.
Was machen wir mit den Daten?
Okay, wir haben jetzt Daten als eine Abfolge von Zahlen. Was machen wir nun damit? Die Grundlage Künstlicher Intelligenz ist intelligente Datenverarbeitung. In den meisten Fällen besteht die Leistung der KI darin, eine Reihe von Ausgangsdaten in eine Menge von Ergebnisdaten zu überführen. Das passiert mit einer Reihe von sogenannten Algorithmen.
3.2 Algorithmen
Wie wir sehen, können die Eingabedaten unterschiedlicher Natur sein: Zahlen, Text, Audio, Bilder, Videos, Ortsangaben usw. Manchmal liegen die Daten bereits maschinenlesbar vor, manchmal müssen diese erst noch umgewandelt werden. Durch Digitalisierung können die Eingabedaten alle in Zahlen umgewandelt werden. KI ermöglicht, auf der der Basis der Eingabedaten sinnvolle Entscheidungen zu treffen. Zwischen den Eingabe- und Ausgabedaten gibt es verschiedene „intelligente“ Verfahren, die aus den Eingabedaten neue Daten erzeugen. Die Intelligenz steckt also in den „intelligenten“ Verfahren.
Solche Verfahren der Datenverarbeitung nennen wir Algorithmen. Ein Algorithmus ist eine eindeutige Beschreibung, wie Daten verarbeitet werden sollen. Ein Anwendungsbeispiel, das du in deinem Smartphone oder Laptop vielleicht schon einmal gesehen hast, ist ein Fotofilter, z.B. bei Instagram. Ein Fotofilter liest ein Foto ein und verändert dieses, indem er z.B. die Farben verstärkt oder die Kontraste erhöht. Ein extrem simpler Filter wäre ein Filter, der aus einem Schwarz-Weiß-Bild ein Negativbild macht, also Schwarz und Weiß vertauscht.
Ein Algorithmus, der das Negativbild zu unserem digitalisierten „A“ herstellt, lautet: Nimm die digitalisierten Zahlen des Bildes und wandle jede 1 in eine 0 um und jede 0 in eine 1, oder noch genauer: Gehe zeilenweise durch das Zahlengitter: Immer, wenn du in einem Feld auf einen 0 triffst, mache eine 1 daraus, und wenn du auf eine 1 triffst, mache eine 0 daraus. Das ist natürlich ein sehr simpler Algorithmus, der aber sehr gut funktioniert. Praktisch kann ein Algorithmus in einem Computer beliebig komplexe Berechnungen mit den Eingabedaten anstellen.
Schaubild: Was ist ein Algorithmus? Und Illustration zum Fotofilter (fehlt noch). Es gibt zwei Möglichkeiten, wie Algorithmen uns bei der „intelligenten“ Datenverarbeitung unterstützen:
Regelbasierte Algorithmen und Lernende Algorithmen.
3.2.1 Regelbasierte Algorithmen
Hierbei wird alles Wissen durch ganz klare Regeln in den Prozess vom Entwickler in die Maschine „hineinprogrammiert“, so wie bei dem Negativfilter oben. Das heißt, eine Reihe von unveränderbaren Regeln legt fest, was mit den Ausgangsdaten passieren muss, um zu den Ergebnisdaten zu gelangen. Der Vorteil solcher regelbasierter Algorithmen ist, dass sie sicher und schnell zu einem eindeutigen Ergebnis führen und dass die Art, wie der Algorithmus dort hingekommen ist, einfach nachvollziehbar ist. Ein Nachteil ist, dass jedes neue Wissen explizit in Regeln formuliert werden muss und nur das bereits Einprogrammierte auch wieder verwendet werden kann.
Schaubild (to do)
Ausgangsdaten —> Regeln
Neue Daten —> Regeln —> Ergebnis
3.2.2 Lernende Algorithmen
Hierbei wird das Wissen nicht explizit in den Algorithmus eingeschrieben, sondern es werden Beispiele präsentiert, aus denen der Algorithmus selber „lernt“, was die Ausgabe sein soll. Ein Vorteil dieser lernenden Algorithmen besteht darin, dass diese durch neue Daten immer wieder etwas Neues lernen können. Man braucht keinen Programmierer, der alle Daten in Regeln umformuliert, sodass diese Verfahren viel flexibler sind als vorprogrammierte Systeme.
Schaubild:
Trainingsdaten —> Lernender Algorithmus —> Modell
Neue Daten —> Modell —> Ergebnis
Aus den sogenannten Trainingsdaten entsteht ein Modell. Nach der Trainingsphase kann das Modell verwendet werden, um neue Daten zu verarbeiten.
Beispiel: Ich zeige dem Algorithmus Hunderte verschiedene Bilder von Zahlen. und der Algorithmus entwickelt daraus ein internes Modell.
Etwa so: Ein gerader Strich von oben nach unten entspricht einer 1, ein geschlossener Kreis oder Oval entspricht einer 0 usw.
Nachdem der lernende Algorithmus sich von all den präsentierten Bildern ein Modell gemacht hat, kann man mit dem Modell neue, auch leicht abweichende Bilder von Zahlen richtig einsortieren.
Das Modell kann eine einfache mathematische Formel sein oder eine super-komplizierte Berechnung. Entscheidend ist, dass es die Eingabedaten allein durch Berechnung in Ausgabedaten umwandelt. Wie das genau funktioniert, werden wir in den nächsten Kapiteln an vielen Beispielen sehen.
Wir merken uns:
Die Verfahren, die aus unseren Daten ein Modell trainieren, nennen wir Lernende Algorithmen.
Bei den Lernenden Algorithmen unterscheiden wir drei Formen:
3.2.2.1 Überwachtes Lernen
Ein „Trainer“ sagt der Maschine bei jedem Beispiel, welches die richtigen Ergebnisse sein sollen; und zwar so lange, bis die Maschine es verstanden hat. Bis sie z.B. bei jeder neuen Mail erkennt, ob diese Spam oder kein Spam ist.
3.2.2.2 Unüberwachtes Lernen
Hierbei wendet der Algorithmus statistische Methoden an, um die unstrukturierten Daten in eine neue Ordnung zu bringen, ohne dass ein Mensch dabei „vorsagt“, was richtig oder falsch ist. Damit kann der Algorithmus Zusammenhänge in den Daten entdecken, die der Mensch selbst vorher nicht erkannt hat. Ein Beispiel ist die automatische Zuordnung von Kunden beim Online-Shopping in verschiedene Gruppen durch Analyse des Kaufverhaltens. Das Modell kann danach z.B. Vielkäufer von Gelegenheitsshoppern unterscheiden. (Dazu kommen wir in Kapitel 9.)
3.2.2.3 Verstärkendes Lernen/Reinforcement Learning
Hierbei wird der Algorithmus wie ein Hund dressiert. Mit den Ausgangsdaten probiert der Algorithmus verschiedene Lösungen aus, und je nachdem, ob diese nützlich sind oder nicht, erhält er eine Belohnung oder Bestrafung nach einem Punktesystem. Am Ende wird das gemacht, was am meisten Punkte bringt. Auch dieses Lernen ist eine Form des überwachten Lernens, da ein Trainer über die Punkte entscheidet, die das jeweilige Verhalten bewerten. Beispiele für Verstärkendes Lernen finden wir in Computer-Games, Schachprogrammen und bei automatischen Staubsaugerrobotern. (Das sehen wir uns in Kapitel 10 an.)
3.3 Modelle
Was ist also nun ein Modell? Fürs Erste können wir folgende Definition verwenden:
Ein Modell wandelt Eingabedaten in Ausgabedaten um.
Dabei kann das Modell einen einfachen mathematischen Zusammenhang beschreiben oder ein sehr komplexes Verfahren darstellen, das durch viele Beispiele von Trainingsdaten trainiert wurde.
Beispiel für ein einfaches Modell:
Ich stelle fest, dass eine neue Prepaidkundin in den ersten drei Monaten etwa 25 Euro monatlich für Datenverkehr mit ihrem Handy ausgibt. Ein einfaches Modell, um den Jahresumsatz zu berechnen, wäre nun, den Monatsumsatz mit 12 zu multiplizieren. So erhalte ich als vorhergesagten Jahresumsatz: 25 Euro x 12 = 300 Euro.
Ein komplexeres Modell schaut sich mehrere verschiedene Kunden an, z.B. eine Stichprobe von 300, und stellt fest, dass 100 Kunden etwa 10 Euro im Monat ausgeben, weitere 100 Kunden etwa 20 Euro und noch andere 100 Kunden etwa 30 Euro. Das zugehörige Modell für den Jahresumsatz ist nun komplizierter: Zuerst errechne ich den durchschnittlichen Monatsumsatz der Stichprobe: (100 x 10 Euro + 100 x 20 Euro + 100 x 30 Euro) : 300 = 20 Euro.
Dann multipliziere ich den durchschnittlichen Monatsumsatz mit 12, das ergibt einen Jahresumsatz: 20 x 12 = 240 Euro.
Zum einen ist das zweite Modell besser als das erste, weil es auf der Basis von detaillierteren Kundendaten zustande kommt, zum anderen werden im zweiten Modell drei Typen von Kunden zusammengeworfen, über die man viel mehr herausbekommen könnte, wenn man sie mit einem noch komplexeren Modell als drei verschiedene Kundengruppen betrachten würde.
Ein Modell hilft uns dabei, Vorhersagen zu machen.
Später werden wir z.B. beim Maschinellen Lernen Modelle kennenlernen, die automatisch auf der Basis von Eingabedaten Prognosen über die Ausgabedaten machen können, ohne dass wir eine mathematische Formel dort einprogrammieren müssen. Hier schon mal eine kleine Vorschau, was wir uns dabei anschauen werden:
Weitere Beispiel für Modelle:
| Eingabe | Ausgabe | Modell |
| Eigenschaften von einem Tier | Genaue biologische Bestimmung des Tieres | Expertensystem |
| Preise von gebrauchten Handys | Preis für ein Handy mit einem bestimmten Alter | Preisvorhersage-Modell |
| Stunden, die man für eine Prüfung lernt | Wahrscheinlichkeit, mit der man die Prüfung besteht | Vorhersagemodell |
| Filme, die man schon gesehen hat | Vorschlag für einen neuen Film, der einem gefallen könnte | Empfehlungsmodell |
| Verschiedene Songs | Gruppierung zu einem Musik-Typ | Gruppierungsmodell |
| Karte von einer Umgebung | Bester Weg zu einem Ziel | Zielfindungsmodell |
| Bestimmte Verhaltensweisen | Einordnung als Zombie oder Mensch | Klassifikationsmodell |
| Fragen zu einem Thema | Antworten | Sprachassistent |
Alle diese Modelle werden wir uns in den nächsten Kapiteln genauer ansehen.
Links zum Inhalt:
Die Reflexe des Neugeborenen: https://www.swissmom.ch/baby/medizinisches/das-neugeborene/die-neugeborenenreflexe/
Vögel imitieren Klingeltöne: https://www.nabu.de/news/2005/03960.html
Krähen knacken Nüsse: https://www.brodowski-fotografie.de/beobachtungen/kraehe-knackt-nuss.html
Papageien schlauer als Hunde und Kleinkinder: https://www.sueddeutsche.de/wissen/denkleistungen-bei-tieren-papageien-beherrschen-logik-wie-menschenaffen-1.1435515
Video, das erklärt, wie analoge in digitale Daten umgewandelt werden.