Curriculum
KISS* - KI für Schüler*innen und Studierende
Einführung
0/7KI - Technik und Anwendungen
0/20-
4 Regelbasierte KI - Expertensysteme
 Vorschau
Vorschau -
• Check zu Expertensysteme
Vorschau
-
5 Maschinelles Lernen / Machine Learning (ML)
Vorschau
-
• Check zu Maschinelles Lernen
Vorschau
-
6 Überwachtes Lernen I - Lineare Regression
Vorschau
-
• Interaktiv Lineare Regression 1
Vorschau
-
• Interaktiv Lineare Regression 2
Vorschau
-
• Check Lineare Regression Wissensfragen
Vorschau
-
7 Überwachtes Lernen II – Logistische Regression und Klassifikation
Vorschau
-
• Check zu Logistische Regression und Klassifikation
Vorschau
-
8 Empfehlungssysteme
Vorschau
-
• Check zu Empfehlungssysteme
Vorschau
-
9 Unüberwachtes Lernen - Clustering
Vorschau
-
• Check zu Clustering
Vorschau
-
10 Verstärkendes Lernen
Vorschau
-
• Check zu Verstärkendes Lernen
Vorschau
-
11 Künstliche Neuronale Netze
Vorschau
-
• Check zu Künstliche Neuronale Netze
Vorschau
-
12 Chat-Bots und Sprachassistenten
Vorschau
-
• Check zu Chat-Bots und Sprachassistenten
Vorschau
KI und Philosophie
0/3Materialien
0/111 Künstliche Neuronale Netze
Bei der Nachahmung menschlicher Intelligenz hat man sehr lange auf immer schnellere und immer größere Computer gesetzt. Oft wurden Tausende Computer zusammengeschaltet, um ein bestimmtes Problem zu lösen. Dabei passt das intelligenteste System, das wir auf der Erde kennen, in einen Schuhkarton, wiegt nicht mehr als drei Pfund und verbraucht nicht mehr Energie als eine Glühbirne: das menschliche Gehirn.
Daher kam man irgendwann auf die Idee, etwas genauer in das Gehirn hineinzuschauen, um intelligente Leistungen besser zu verstehen. Und tatsächlich konnte man mit dieser Vorgehensweise viele Aufgaben der KI noch besser und eleganter lösen. Aus den Erkenntnissen der Hirnforschung schuf man Teile von künstlichen Gehirnen und nannte diese Künstliche Neuronale Netze, kurz KNN (engl. Artificial Neural Networks, kurz: ANN).
Was ist das?
Künstliche Neuronale Netze
Künstliche Neuronale Netze orientieren sich am Aufbau biologischer neuronaler Netze in einem menschlichen (oder tierischen) Gehirn. Aus der Biologie wissen wir schon sehr viel über den Grundaufbau von biologischen Gehirnen. Er ist selbst bei primitiven Lebewesen ziemlich ähnlich strukturiert wie bei höher organisierten Tieren und beim Menschen.

( “Texture of the Nervous System of Man and the Vertebrates” by Santiago Ramón y Cajal. The figure illustrates the diversity of neuronal morphologies in the auditory cortex. Gemeinfrei via Wikipedia )

Abb: Modell des Neuronalen Netzes eines Fadenwurms: https://upload.wikimedia.org/wikipedia/commons/0/03/C.elegans-brain-network.jpg Mentatseb / CC BY-SA (https://creativecommons.org/licenses/by-sa/3.0)
{kind=link}
Selbst bei einem Fadenwurm mit 300 Nervenzellen, der noch nicht sonderlich viel kann, sieht das schon ziemlich kompliziert aus. Und je intelligenter der untersuchte Organismus ist, umso komplexer wird das Geflecht von neuronalen Zellen.
Bei einer Ratte sind das schon etwa 200 Millionen Neuronen, ein Mensch soll neueren Untersuchungen zufolge durchschnittlich knapp 100 Milliarden Nervenzellen haben. Da jede dieser Nervenzellen beim Menschen durchschnittlich mit ca. tausend anderen verbunden ist, ergibt das etwa 100 Billionen Verbindungen. Das Erstaunliche ist ja, wie bereits erwähnt, dass all das in einen menschlichen Kopf passt und nicht mehr Energie verbraucht als das Ladenetzteil von einem größeren Desktop-Computer. Beim energetischen Fußabdruck ist der Mensch jedem Computer noch meilenweit voraus. Mit der Energie einer Schüssel Haferflocken mit Früchten kann das menschliche Gehirn Hunderttausende Bilder und Töne klassifizieren, jede Menge Cluster bilden und nebenbei noch durch das Labyrinth einer Großstadt navigieren. Wie gelingt das einem Neuronalen Netz?
Sieht man sich die einzelnen Nervenzellen, die man auch Neuronen nennt, unter einem Mikroskop an, so erkennt man, dass diese jeweils aus einem dickeren Ende, dem sogenannten Dendriten, bestehen, von dem mehrere lange Fäden, sogenannte Axone, abgehen. Diese Axone docken an ihrem Ende über die Synapsenan andere Nervenzellen an. Über Axone und Synapsen können von Nervenzellen biochemisch aktiviertwerden. Die biochemischen Details kann man u.a. bei Wikipedia nachlesen: (https://de.wikipedia.org/wiki/Nervenzelle)
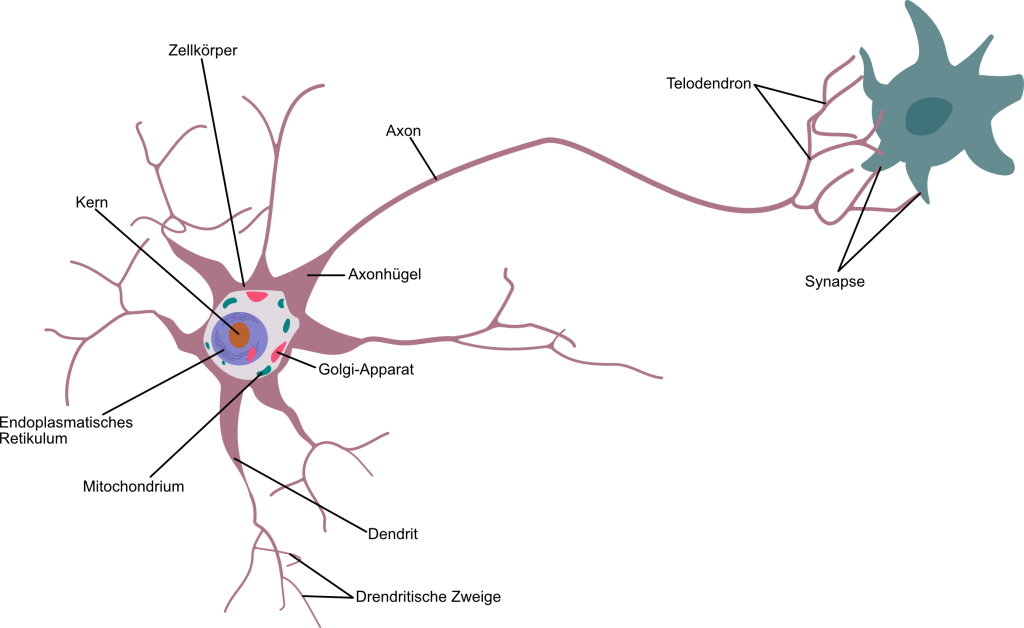
Zugegeben, das sieht ziemlich verworren und glibberig aus. Für die Modellierung von Künstlichen Neuronalen Netzen interessiert uns nur die prinzipielle Funktionsweise, die sich vereinfacht folgendermaßen darstellen lässt.

Aktivierungen, die zum Beispiel über Sinneszellen (Augen, Ohren) in das Neuronale Netzwerk hineinkommen (im Schaubild links), fließen über die Verbindungslinien (vergleichbar den Axonen) zu weiteren Nervenzellen und dann über noch mehr Verbindungen zu wieder weiteren (rechts). Dabei kann es sein, dass diese Vernetzung sehr komplex ist (im linken Teil des Netzes sind alle grünen mit allen blauen Zellen verbunden) oder auch eher einfach (rechts fließen alle Aktivierungen der blauen Zellen zusammen in die gelbe Zelle).
Das sieht im Schaubild zunächst nicht sehr leistungsfähig aus. Bedenkt man aber, dass ein Mensch um die 100 Milliarden Neuronen mit ca. 100 Billionen Verbindungen besitzt, kann man sich vorstellen, dass damit auch komplexe Aufgaben gelöst werden können.
Was wir schon einmal festhalten können: Prinzipiell eignet sich ein Neuronales Netz hervorragend, um Eingangsdaten zu verarbeiten und daraus Ergebnisdaten zu generieren, was wir ja als Kernfunktion der KI erkannt haben.
Wir erinnern uns: Die Grundlage Künstlicher Intelligenz ist eine intelligente Datenverarbeitung. In den meisten Fällen besteht die Leistung der KI darin, eine Reihe von Ausgangsdaten in eine Menge von Ergebnisdaten zu überführen. Im Unterschied zum Expertensystem fällt bei dieser Art von Datenverarbeitung auf, dass wir keine separate Wissensbasis haben, wo das Wissen abgelegt wird, und dass die Verarbeitung nicht Schritt für Schritt (sequentiell), sondern parallel an vielen Stellen gleichzeitig erfolgen kann. Wir werden später sehen, dass diese beiden Eigenschaften (verteilt und parallel) in einem Neuronalen Netz viele Vorteile gegenüber dem linearen Computermodell haben.
Als Nächstes schauen wir uns an, wie ein Künstliches Neuronales Netz etwas lernen kann und auf diese Weise intelligente Leistungen erbringt.
Dieses Video erklärt sehr schön, wie eine Klassifizierung in einem Neuronalen Netz gelernt wird:
Wir erinnern uns an den generellen Ablauf beim Maschinellen Lernen.
Aufgabe: Unterscheide Katzen- von Hundebildern.
Material: 1000 Katzenbilder und 1000 Hundebilder.
Trainingsphase: Ich trainiere das Modell der KI mit 800 Katzen- und 800 Hundebildern.
Testphase: Wenn das Modell fertig trainiert ist, nimmt man die übrig gebliebenen 200 Katzen- und Hundebilder und überprüft, ob diese richtig erkannt werden. Falls die Fehlerquote zu hoch ist, muss man das Modell noch einmal überdenken.
Einsatzphase: Ist die Fehlerquote gering, sodass die meisten Katzen und Hunde richtig erkannt werden, kann das Modell im Alltag eingesetzt werden.
In dem Video sehen wir, was das Besondere des Lernens in Neuronalen Netzen ist. Die Weise, wie die einzelnen Neuronen miteinander verbunden sind, wird beim Lernen angepasst. Prinzipiell gilt dabei: Diejenigen Verbindungen, die für die Aufgabe zu besseren Ergebnissen führen, werden verstärkt; diejenigen, die zu schlechteren Ergebnissen führen, werden abgeschwächt. Dadurch kann das Netzwerk ganz fein abgestimmt werden, bis es seine Aufgabe perfekt erledigt. (Ein bisschen ist das so wie beim Reinforcement Learning, da wird ja auch gutes Verhalten „belohnt“ und schlechtes „bestraft“.)
Wir wollen jetzt selbst ein kleines Neuronales Netz basteln, und damit ein paar Dinge ausprobieren. Zunächst schauen wir uns ein einzelnes Neuron an. Damit es nicht so dröge wird, wollen wir mit dem Neuron einen Zombie-Detektor bauen. Auf der linken Seite haben wir die Eingangswerte, da werden die Informationen z.B. von den Sinnesorganen (Augen, Ohren) oder anderen Neuronen eingespeist. Die unterschiedlichen Eingaben werden unterschiedlich gewichtet und anschließend addiert. Man kann sich gut vorstellen, dass bei einer Klassifikation einige Merkmale großes Gewicht haben, andere dagegen weniger oder sogar irrelevant sind. Wollen wir z.B. Zombies von Menschen unterscheiden, so ist die Kleidung irrelevant, denn Zombies können die gleiche Kleidung tragen wie Menschen. Die Augenbewegungen von Menschen hingegen sind lebendig, während Zombies einen toten Blick haben. Also müsste man die Augenbewegung bei der Erkennung hoch gewichten, die Kleidung aber ignorieren.
Nun könnte es sein, dass einige Menschen bereits etwas müde sind und die Augenbewegungen nicht mehr ganz so lebhaft. Daher ist es vorteilhaft, weitere Merkmale hinzuzunehmen, z.B. ob das zu bestimmende Wesen Blut im Gesicht hat. Wenn das der Fall ist, dann ist es wahrscheinlich ein Zombie, denn der stört sich nicht daran. Ein Mensch hingegen versucht sich das Blut abzuwischen, deshalb trifft man kaum Menschen an, die mit Blut im Gesicht herumlaufen. Also würde man das Merkmal „Blut im Gesicht“ ebenfalls hoch gewichten usw.
Hat man alle Merkmale eingespeist, dann werden die Werte am Eingang der Neuronen mit ihren Gewichtungen multipliziert und am Ende addiert, das macht das Sigma-Zeichen in der Mitte. Das Ergebnis wird nun weitergegeben an eine Aktivierungsfunktion, die prüft, ob ein bestimmter Schwellwert über- oder unterschritten wird. Wenn dass der Fall ist, wird die Aktivierung weitergegeben, das heißt in unserem Fall: Zombie-Alarm!
Beispiel: Als Nächstes wollen wir uns ansehen, wie ein Neuronales Netzwerk lernt und anschließend Klassifikationsaufgaben erledigen kann. Wir vergleichen noch einmal, wie das z.B. ein Expertensystem lösen würde. Es würde eine Wissensbasis geben, wo die Merkmale eingetragen sind, und eine Inferenzmaschine, die diese Merkmale checkt und ein Ergebnis formuliert.
Expertensystem: Zombie oder Mensch
| Zombie | ||
| Augen | starr | |
| Blut im Gesicht | Ja | |
| Kann reden | nein | |
| Haut | kaputt | |
| Bewegung | eckig | |
| Mensch | ||
| Augen | lebendig | |
| Blut im Gesicht | Nein | |
| Kann reden | ja | |
| Haut | Glatt | |
| Bewegung | Normal |
Nun schauen wir uns an, wie man eine solche Klassifikationsaufgabe mit einem Neuronalen Netz lösen kann. Das Schaubild soll die Trainingsdaten für unser Neuronales Netzwerk darstellen, es handelt sich um Beobachtungsdaten aus der Zombie-Apokalypse. In der X-Richtung, also nach rechts, wird die Lebendigkeit der Augenbewegungen dargestellt. 0 heißt starre Augen, 1 bedeutet lebhafte Augen. In der Y-Richtung, also nach oben, wird dargestellt, wie viel Blut das Wesen im Gesicht hat. 1 heißt viel Blut, und weniger als 1 weniger Blut. Unsere Testdaten zeigen zwei Gruppen: eine oben links (rot), sie ist relativ klein, die Wesen in dieser Gruppe haben jeweils viel Blut im Gesicht und starre Augen. Die andere (grüne) Gruppe hat manchmal etwas starre Augen, aber kaum Blut im Gesicht, oder sie hat etwas Blut im Gesicht, dafür aber lebendige Augen.

Zum Klassifizieren nehmen wir ein super simples Neuronales Netz. Dieses besteht aus einem einzigen Neuron. Dieses Neuron hat zwei Eingänge (blau) und einen Ausgang (rot).


Am Anfang ist das Neuronale Netz noch untrainiert und kann nicht richtig klassifizieren. Schau dir mal die rote Treppenlinie an: Alles, was im roten Bereich ist, sieht das neuronale Netz als Zombies an, und alles, was im grünen Bereich liegt, als Nicht-Zombies. Das Problem ist, dass am Anfang das Netz gar keinen Zombie erkennt, und das ist ziemlich schlecht. In den nun folgenden Trainingsläufen werden die Gewichtungen von den blauen zum roten Neuron immer weiter so angepasst, dass das Ergebnis der Klassifizierung besser wird.
Nach fünf Lernschritten sieht das Ganze dann so aus:

Die Gewichtungen wurden so angepasst, dass das Blut im Gesicht stärker gewichtet wird und damit die Zombies besser klassifiziert werden. Nun sind nur noch zwei Zombies falsch einsortiert. Nach 15 Lernphasen sieht es so aus, dass alle Zombies richtig klassifiziert werden. Man beachte, wie die Gewichtungen der beiden Merkmale „Blut“ und „starre Augen“ so angepasst werden, dass der Mix aus diesen Eingabedaten eine fehlerfreie Klassifizierung ermöglicht.

Das Ganze ist keine Zauberei, sondern reine Mathematik. Als Berechnungsvorschrift heißt das linke Schaubild:
Nimm den Wert für Lebendige Augen (X), multipliziere diesen mit 0,31, nimm dann den Wert für Blut im Gesicht (Y) und multipliziere ihn mit -0,29; addiere die Ergebnisse dieser beiden Rechnungen und schaue, ob das Ergebnis größer oder kleiner als 0 ist.
Wenn es kleiner als 0 ist, dann ist es ein Zombie.
Beispiel: 0,1 x 0,31 + 1 x – 0,29 = – 0,259; das ist kleiner als 0, also Zombie.
Selbstcheck: Was wäre nach diesem Schema ein Wesen, das sehr lebendige Augen hat und gar kein Blut im Gesicht (X = 1 und Y = 0)?
Was ist eine Gestalt genau in der Mitte (also X = 0,5 und Y = 0,5)?
Ist das nicht genial – ein Super-Mini-Hirn mit nur einer Gehirnzelle kann Zombies von Menschen unterscheiden! Nun können wir uns vorstellen, dass kompliziertere „Gehirne“ noch viel kompliziertere Aufgaben lösen können.
Wir halten noch einmal fest, wie das Neuronale Netz das gemacht hat.
1 Aufgabe: Klassifikation von Zombies vs. Menschen
2 Daten: Videos mit Blut im Gesicht und Augenbewegungen
3 Trainingsphase: Die Trainingsdaten werden nacheinander in das Netz eingespeist und es wird geschaut, welcher Wert am Ende herauskommt. Wenn der Wert falsch ist, dann werden die Gewichtungen, die zu diesem Ergebnis führen, leicht angepasst. (In der Fachwelt sagt man, man korrigiert die Fehler durch einen Backpropagation-Algorithmus; Backpropagation heißt: man geht vom Ergebnis aus rückwärts durch das Netzwerk und passt je nach der Größe der Fehler die Gewichtungen an.) Nach mehreren Runden des Trainings werden die Gewichtungen so eingestellt, dass sie die Beispiel alle (oder zumindest die meisten) richtig klassifiziert. Dann ist das Modell fertig trainiert und kann zur Klassifikation eingesetzt werden.
4 Testphase: Hier würde man das Netz noch mit ein paar Beispielen, die man noch nicht trainiert hat, testen, um zu überprüfen, ob es auch neue Fälle richtig klassifiziert. Den Part haben wir in unserem Beispiel ausgelassen, aber zur Sicherheit, damit nicht doch am Ende ein paar Zombies durchschlüpfen, würde man das sicher noch mal mit ein paar neuen Beispielen evaluieren ;-).
5 Einsatzphase: Das Netz kann nun verwendet werden, um neue Fälle zu klassifizieren.
Wenn du das Beispiel noch einmal interaktiv selber ausprobieren willst, dann klicke auf diesen Link:
Vom Simpel-Hirn zum Deep Learning
Das Konzept für ein Simpel-Hirn wie in unserem Beispiel gibt es schon seit den 1950er-Jahren, das Modell nennt sich einlagiges Perzeptron (https://de.wikipedia.org/wiki/Perzeptron).
Wie bereits gesagt kann man nach dem neuronalen Grundmodell wie mit Legosteinen beliebig komplexe Neuronale Netze aufbauen. Die aufeinanderfolgenden Schichten von Neuronen nennt man Layer und ein vielschichtiges Neuronales Netz auch tiefes Neuronales Netz (engl. Deep Neural Network), die dazugehörigen Lernalgorithmen heißen dementsprechend Deep Learning Algorithmen.
Wo das Perzeptron einfache Aufgaben erledigt, können die Deep Neural Networks richtig komplexe Klassifikationen durchführen. Im Prinzip funktioniert das Lernen aber genauso, wie oben beschrieben. Im Video oben hast du ja schon ein etwas komplexeres Netz gesehen, hier kommt noch mal ein schönes Beispiel, an dem du ein wenig herumprobieren kannst. Es handelt sich um ein Neuronales Netz, das handgeschriebene Zahlen klassifizieren kann. Zwischen der Eingabeschicht und dem Ausgabe-Layer finden wir 6 Schichten/Layer von Neuronen, die am Ende die Eingabe klassifizieren können.
https://www.cs.ryerson.ca/~aharley/vis/conv/
Das Besondere hieran ist, dass die Neuronen in den ersten Schichten nach bestimmten Grundmustern suchen (z.B. geraden Linien oder Halbkreisen, Kanten und Winkel) und die nächsten Schichten dann aus diesen Grundmustern die Form der Ziffern zusammenzusetzen versuchen. (So ein Netz nennt man Convolutional Neural Network, das musst du dir aber nicht merken.)
Das führt dazu, dass viele Variationen von Ziffern richtig erkannt werden. Versuche einmal, bei der Eingabe ein Zwischending zwischen 1 und 7 einzugeben, dann stellst du fest, dass das Netzwerk dann ebenso wie ein Mensch nicht mehr richtig klassifizieren kann. Auch Neuronale Netze sind nicht unfehlbar, aber in weiten Bereichen fehlertolerant, d.h. sie akzeptieren viele Varianten bei den Eingabedaten.
Vorteile/Nachteile
Vorteile:
– Neuronale Netze sind für Klassifikationsaufgaben hervorragend geeignet. Zudem sind sie fehlertolerant, d.h. kleine Abweichungen bei den Eingabedaten stören die Klassifikation nicht.
Nachteile:
– Man muss besonders bei Deep Neural Networks sehr viel rechnen, das kostet Rechenpower und Strom.
– Komplexe Klassifikationsaufgaben erfordern in der Trainingsphase sehr viele Beispiele, was noch mehr Rechenpower und Strom verbraucht. Verfügt man nicht über genügend viele gute Beispiele zum überwachten Lernen, nützen einem auch große und komplexe Modelle nichts.
Wirtschaftliche Bedeutung
Neuronale Netze und Deep Learning sind die momentan wichtigsten KI- Methoden. Große Technologiefirmen wie Google, Amazon oder Microsoft investieren Milliarden in der Hoffnung, immer komplexere Aufgaben erledigen zu können. Insbesondere in einzelnen Bereichen der Sprach-, Bild- und Videoerkennung erreichen diese KI-Techniken die Fähigkeiten von Menschen oder übersteigen diese. So können noch mehr Aufgaben, für die bisher Menschen benötigt werden, automatisiert werden. Dies betrifft insbesondere hochqualifizierte Aufgaben wie z.B. das Übersetzen von Sprachen. Wegen der hohen benötigten Rechenleistungen wird viel in neue Hardware investiert. Google, Amazon und Microsoft betreiben riesige Datencenter mit besonders schneller Spezialhardware, die sie auch anderen Firmen als Dienstleistung anbieten. Da man sich viel von diesen neuen Technologien verspricht, arbeiten auch die besten Forscher und Entwickler in diesem Bereich. Kosten spielen hier keine Rolle, denn wenn ein Problem einmal durch ein gutes Neuronales Modell gelöst ist, kann man dieses endlos kopieren und überall einsetzen.
Gesellschaftliche Bedeutung
Insbesondere bei der Verwendung der KI zum Verstehen der menschlichen Sprache scheint eine neue Schwelle überschritten zu werden. Nicht nur, dass wir mit Siri und Alexa nun digitale Assistenten haben, die unsere Fragen direkt verstehen und beantworten; dadurch, dass Roboter uns nun verstehen und uns in natürlicher Sprache antworten, entsteht der Eindruck, dass diese Roboter „menschenähnlicher“ werden. Wir ordnen diesen Robotern immer mehr menschliche Eigenschaften zu und vertrauen ihnen zunehmend. Das könnte in vielen Bereichen zu einem Verwischen der Grenze zwischen Mensch und Maschine führen. (Siehe dazu auch das Kapitel 13.)