Curriculum
KISS* - KI für Schüler*innen und Studierende
Einführung
0/7KI - Technik und Anwendungen
0/20-
4 Regelbasierte KI - Expertensysteme
 Vorschau
Vorschau -
• Check zu Expertensysteme
Vorschau
-
5 Maschinelles Lernen / Machine Learning (ML)
Vorschau
-
• Check zu Maschinelles Lernen
Vorschau
-
6 Überwachtes Lernen I - Lineare Regression
Vorschau
-
• Interaktiv Lineare Regression 1
Vorschau
-
• Interaktiv Lineare Regression 2
Vorschau
-
• Check Lineare Regression Wissensfragen
Vorschau
-
7 Überwachtes Lernen II – Logistische Regression und Klassifikation
Vorschau
-
• Check zu Logistische Regression und Klassifikation
Vorschau
-
8 Empfehlungssysteme
Vorschau
-
• Check zu Empfehlungssysteme
Vorschau
-
9 Unüberwachtes Lernen - Clustering
Vorschau
-
• Check zu Clustering
Vorschau
-
10 Verstärkendes Lernen
Vorschau
-
• Check zu Verstärkendes Lernen
Vorschau
-
11 Künstliche Neuronale Netze
Vorschau
-
• Check zu Künstliche Neuronale Netze
Vorschau
-
12 Chat-Bots und Sprachassistenten
Vorschau
-
• Check zu Chat-Bots und Sprachassistenten
Vorschau
KI und Philosophie
0/3Materialien
0/17 Überwachtes Lernen II – Logistische Regression und Klassifikation

Während die Regression den Zusammenhang von verschiedenen Zahlen in eine mathematische Formel abzubilden versucht, geht es bei der Klassifikation darum, dass verschiedene Werte in bestimmte Kategorien einsortiert werden sollen. Das kann eine total simple Kategorisierung sein wie z.B. Prüfung bestanden oder Prüfung nicht bestanden, oder eine sehr komplizierte Klassifikation mit Tausenden von Klassen, z.B. die Erkennung eines Wortes aus einem Vokabular von 30.000 Wörtern in einem Sprachassistenten.
Was ist das?
Logistische Regression
Die Logistische Regression ermöglicht eine einfache Form der Klassifikation. Sie wird dann eingesetzt, wenn eine Reihe von Ausgangswerten in zwei oder mehr Klassen abgebildet werden sollen, aber diese Zuordnung nicht aufgrund von Regeln, sondern aufgrund von Wahrscheinlichkeiten erfolgt.
Beispiel: Manche Studierende müssen für eine Prüfung sehr, sehr lange lernen, manchen fällt es hingegen leicht, sich auf eine Prüfung vorzubereiten. Es gibt keine Garantie, dass sehr langes Lernen immer zum Bestehen einer Prüfung führt. Zu kurzes Lernen führt häufig dazu, dass man durchfällt. Aber eben nicht immer und für alle. Es ist jedoch wahrscheinlich, dass man mit viel Lernen erfolgreicher ist.
Einige Gedanken zu Wahrscheinlichkeiten
In vielen Fällen aus dem Alltag gibt es keine absoluten Gewissheiten, sondern nur bestimmte Wahrscheinlichkeiten: z.B. dass mit längerem Lernen der Prüfungserfolg steigt. Wäre es nicht so, wäre Lernen insgesamt sinnlos. Auch viele ML-Methoden machen nur Wahrscheinlichkeitsaussagen, statt zu behaupten, etwas wäre zu 100 Prozent sicher. Das klingt zunächst seltsam, aber in unserem Alltag ist sehr viel mehr von Wahrscheinlichkeiten bestimmt als von Gewissheiten. Kein Mensch kann mit Gewissheit sagen, dass er heute nicht noch einen Unfall haben wird. Aber die Wahrscheinlichkeit, dass das passiert, ist so gering, dass man es als Gewissheit annimmt. Wenn es um komplizierte Zusammenhänge geht, bei denen viele Einflussfaktoren eine Rolle spielen, gibt es selten Gewissheiten bei der Vorhersage durch ML, sondern eine Liste von Wahrscheinlichkeiten, und es ist rational, dass man die wahrscheinlichste Option als Ergebnis wählt.
Wer tiefer in ML einsteigen will, sollte fit sein in Statistik. Aber keine Angst, wir kommen erst einmal mit unserer Intuition aus. Wir haben hier einen Datensatz mit 30 Studierenden. Aufgelistet ist, wie lange diese Studierenden für die Prüfung gelernt haben (Anzahl der Lernstunden) und ob sie die Prüfung bestanden haben (1 = Bestanden, 0 = Durchgefallen). Wir sehen sofort, dass es hier keinen „linearen“ Zusammenhang zwischen Lernstunden und Prüfungsergebnissen gibt. So haben die Studis Nr. 10 und 14 mit 7 Lernstunden nicht bestanden, die Studis Nr. 21 und 26 hingegen haben mit der gleichen Lernzeit bestanden. Man kann die Tendenz ablesen, dass mehr Lernen mehr bringt, aber es gibt auch Ausnahmen. So hat z.B. Superhirn Studi Nr. 15 mit nur 3 Lernstunden die Prüfung geschafft.
Die Lineare Regression aus dem letzten Abschnitt hilft uns also hier nicht weiter. Für solche Fälle gibt es die sogenannte Logistische Regression. Logistische Regression ist ein Verfahren, das auf der Basis der gegebenen Daten ein Wahrscheinlichkeitsbild für den Zusammenhang zwischen Lernstunden und Lernerfolg erstellt. Wohlgemerkt, immer basierend auf den jeweils vorliegenden Daten. Das heißt in der Realität: Für diese Studierendengruppe und diese Prüfung stimmt der errechnete Zusammenhang. Für andere Prüfungen und andere Studierende kann es aber ganz anders aussehen. Dennoch nimmt man an, dass für ähnlich ausgebildete Studierende, die die Prüfung noch nicht abgelegt haben, das Gleiche gelten wird. Das ist die Prognoseannahme: Ähnliche Voraussetzungen führen zu ähnlichen Ergebnissen.
| Studi | Lernstunden | Bestanden | Studi | Lernstunden | Bestanden | |
| 1 | 8 | 1 | 16 | 3 | 0 | |
| 2 | 7 | 1 | 17 | 5 | 0 | |
| 3 | 4 | 0 | 18 | 9 | 1 | |
| 4 | 4 | 0 | 19 | 6 | 0 | |
| 5 | 7 | 1 | 20 | 4 | 0 | |
| 6 | 5 | 0 | 21 | 7 | 1 | |
| 7 | 8 | 1 | 22 | 4 | 0 | |
| 8 | 5 | 0 | 23 | 2 | 0 | |
| 9 | 8 | 1 | 24 | 9 | 1 | |
| 10 | 7 | 0 | 25 | 5 | 0 | |
| 11 | 8 | 1 | 26 | 7 | 1 | |
| 12 | 7 | 1 | 27 | 6 | 1 | |
| 13 | 5 | 0 | 28 | 9 | 1 | |
| 14 | 7 | 0 | 29 | 3 | 0 | |
| 15 | 3 | 1 | 30 | 7 | 1 |

Die Logistische Regression erzeugt aus den Trainingsdaten eine Kurve, die aussieht wie ein langgezogenes „S“. Die Kurve bildet die Anzahl der Lernstunden (X-Achse) in Wahrscheinlichkeiten (Y-Achse) ab. Wahrscheinlichkeiten werden in Zahlenwerten zwischen 0 und 1 dargestellt, wobei 0 heißt: wird bestimmt nicht eintreffen, und 1: wird sicher eintreffen. 0.5 heißt: wird mit 50 prozentiger Wahrscheinlichkeit eintreffen, also genau Halbe-Halbe.
Man sieht im Schaubild, dass man etwa 6 Lernstunden braucht, um mit 50-prozentiger Wahrscheinlichkeit zu bestehen, ab ca. 8 Stunden ist es ziemlich sicher, dass man besteht.
Es gibt in diesem Modell keine absolute Wahrheit, sondern nur abhängige Wahrscheinlichkeiten. Aber das ist gerade die Stärke dieser Algorithmen: Sie erstellen – wir sagen auch gerne „lernen“ – auf der Basis der Eingangsdaten ein Modell, dass uns für die Zukunft hilft, Vorhersagen für ähnliche Daten zu machen.
Was wäre, wenn wir mehr Studierende hätten, die mit weniger Stunden die Prüfung bestehen? Wie wirkt sich das auf unser Modell und die entsprechende Kurvengrafik aus? Was schätzt du?
Antwort: Die Kurve verlagert sich nach links, d.h. nun ist die Wahrscheinlichkeit höher, mit wenig Lernstunden die Prüfung zu schaffen.
Der große Vorzug dieses Modells ist es, dass es Eingabedaten verarbeiten kann, die unscharf sind oder sogar widersprüchlich erscheinen. Wenn man mit 3 – 7 Stunden die Prüfung bestehen kann, dann fragt man sich bestimmt: „Ja was denn nun, 3 oder 7 Stunden?“
Die Abbildung auf eine Wahrscheinlichkeitsfunktion ist perfekt für das Maschinelle Lernen mit echten Daten geeignet, denn wir haben z.B. bei der Bilderkennung viele kleine Abweichungen in den Trainingsdaten, die mit diesem Verfahren verarbeitet werden können. Damit sind dann Aussagen wie „das ist eher eine 1 als eine 7“ möglich. Wie die Abbildung zeigt, gibt es Varianten bei der Handschrift. So kann die nebenstehende Ziffer als 1 oder als 7 aufgefasst werden.
Klassifikation
Logistische Regressionsmodelle ordnen bestimmte Eingangsdaten bestimmten Ausgangsklassen zu, man spricht dabei auch von Klassifikation. In unserem Beispiel gibt es nur zwei Klassen: Bestanden und Nicht-Bestanden. Das Interessante ist, dass Logistische Regression auch für mehr als zwei Klassen verwendet werden kann. Ein schönes Beispiel dafür ist die Handschriftenerkennung. Auf Banküberweisungsformularen oder beim Ablesen des Stromzählers werden z.B. Zahlen in ein Formular eingetragen. Früher mussten diese mühsam von Hand in einen Computer übertragen werden. Heute kann man Handschriften automatisch einlesen und erkennen.
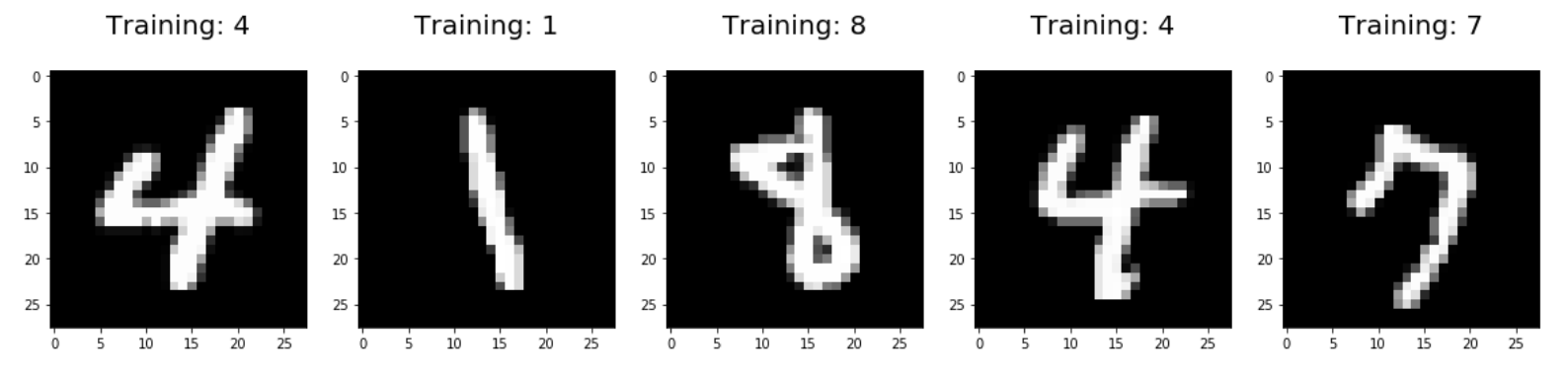
Hierbei haben wir 10 Klassen, in die die Ausgangsdaten eingeordnet werden müssen. Da die Ausgangsdaten eine gewisse Variationsbreite haben (siehe oben die beiden Vieren) kann man nicht einfach ein Bild mit 100% Gewissheit einer Klasse zuordnen, sondern erhält wie bei unserem Beispiel mit den Studierenden Wahrscheinlichkeiten, mit denen ein Abbild einer Klasse zugehörig ist.
Das Gleiche gilt für jede Form von Bilderkennung, z.B. bei Buchstabenerkennung bei der Digitalisierung von Büchern, oder Objekterkennung auf Kamerabildern (Gesichtserkennung). Auch bei der Erkennung von Tönen, z.B. bei der Musik oder Spracherkennung (siehe dazu Kapitel 12) geht es häufig um Klassifikation, z.B. welcher Song ist das oder was hat der Nutzer gerade in sein Handy gesprochen.
Entscheidend ist, dass bei der Klassifikation von Daten mit Logistischer Regression die gleichen Schritte durchlaufen werden, wie bei jedem anderen Machine-Learning-Verfahren.

Neben der Logistischen Regression gibt es noch eine Fülle anderer Klassifikationsmodelle. Viele verwenden heute dafür Neuronale Netze (siehe Kapitel 11).
Wirtschaft
Die Klassifikation von Daten ist eine extrem wichtige Technik in unserem Alltag, wo Sprach-, Sound- und Bilderkennung nicht mehr wegzudenken sind. Auch in der Wirtschaft fallen jede Menge Daten an: Das fängt bei der visuelle Qualitätskontrolle von Produkten in der Fertigung an, und geht bis zu Prognosen in Marketing und Verkauf. Z.B. wie steigt die Wahrscheinlichkeit, dass ein Kunde ein Produkt kauft, wenn ich das Werbebudget erhöhe. Auch in Wissenschaft und Forschung gibt es unendlich viel Anwendungsfälle: Wie gut sind die Heilungschancen, wenn ich die Dosis eines Medikaments erhöhe? Zeigt ein Röntgenbild eine gutartige oder bösartige Veränderung? Alle diese Fragen lassen sich in Klassifikationen abbilden und dann mit Klassifikationsalgorithmen wie der Logistischen Regression untersuchen.
Gesellschaft
Was passiert, wenn Menschen aufgrund von Klassifikationen ein bestimmtes Risiko zugewiesen wird. In den USA gibt es beispielsweise eine Software, die soll z.B. vorhersagen, wie hoch die Rückfallwahrscheinlichkeit von Straftätern ist. Auch bei Schadensversicherungen oder Krankenversicherungen wird bei bestimmten Verträgen berechnet, wie hoch das Risiko ist, dass die Versicherung für einen bestimmtem Vorfall zahlen muss. Denke mal darüber nach, was das für die Gesellschaft bedeuten kann. Und zwar nicht nur, wenn man in eine falsche Kategorie einsortiert wird, sondern dass man überhaupt in Kategorien sortiert wird.